
Figure 1. Self-contained documents
図1 自己完結したドキュメント
Apache CouchDB is one of a new breed of database management systems. This chapter explains why there’s a need for new systems as well as the motivations behind building CouchDB.
Apache CouchDB はデータベース管理システムの新しい血統です。ここでは、なぜ新しいシステムが必要なのか、CouchDB のモチベーションを説明します。
As CouchDB developers, we’re naturally very excited to be using CouchDB. In this chapter we’ll share with you the reasons for our enthusiasm. We’ll show you how CouchDB’s schema-free document model is a better fit for common applications, how the built-in query engine is a powerful way to use and process your data, and how CouchDB’s design lends itself to modularization and scalability.
CouchDB の開発者は CouchDB をごく自然に楽しんで使います。ここでは私たちが熱狂している理由を読者にも感じてもらいたいと思います。CouchDBのスキーマフリーのドキュメントモデルが、ふつうのアプリケーションにいかにフィットするか、組み込みのクエリエンジンがいかにあなたのデータを操作するのに適しているか、そして CouchDB の設計がどのようにモジュール化・スケーラビリティを実現しているかを説明します。
If there’s one word to describe CouchDB, it is relax. It is in the title of this book, it is the byline to CouchDB’s official logo, and when you start CouchDB, you see:
CouchDB を一言であらわすなら、リラックスです。本書のタイトル、公式ロゴの横にもありますし、CouchDBを起動したときにも見ることができます:
Apache CouchDB has started. Time to relax.
Apache CouchDB has started. Time to relax. (CouchDBが起動しました。リラックスの時間です。)
Why is relaxation important? Developer productivity roughly doubled in the last five years. The chief reason for the boost is more powerful tools that are easier to use. Take Ruby on Rails as an example. It is an infinitely complex framework, but it’s easy to get started with. Rails is a success story because of the core design focus on ease of use. This is one reason why CouchDB is relaxing: learning CouchDB and understanding its core concepts should feel natural to most everybody who has been doing any work on the Web. And it is still pretty easy to explain to non-technical people.
なぜリラックスすることが大切なのでしょうか? 開発者の生産性はこの5年でおよそ2倍になりました。最大の理由は、より強力なツールが簡単に使えるようになったからです。たとえば Ruby on Rails です。これはとても複雑なフレームワークですが、使うのは簡単です。Rails は簡単に使えることを最優先して作られたから成功したのです。これが CouchDB がリラックスを掲げている理由のひとつです。つまり、Webで全てを済ませている人なら、CouchDBを学ぶだけで中核の考え方を自然と理解できるようになるでしょう。そして、技術畑でない人にも簡単に理解してもらえることでしょう。
Getting out of the way when creative people try to build specialized solutions is in itself a core feature and one thing that CouchDB aims to get right. We found existing tools too cumbersome to work with during development or in production, and decided to focus on making CouchDB easy, even a pleasure, to use. Chapters 3 and 4 will demonstrate the intuitive HTTP-based REST API.
他に方法がなくて、創造力あふれる人たちがあることに特化しようとしたときに CouchDB はそこに当てはまることを目的にしています。こういうとき、開発の間中もしくはサービス中に既存のツールでやっていくのはかなり面倒です。そこで、CouchDB をより簡単に扱えるようにし、場合によっては楽しくなるようにしようと決めました。「さあ、始めよう」「Core API」の章で、直観的なHTTPベースのREST APIをお見せします。
Another area of relaxation for CouchDB users is the production setting. If you have a live running application, CouchDB again goes out of its way to avoid troubling you. Its internal architecture is fault-tolerant, and failures occur in a controlled environment and are dealt with gracefully. Single problems do not cascade through an entire server system but stay isolated in single requests.
CouchDB ユーザのためのもうひとつのリラックスは、本番での設定です。もしアプリケーションが稼働中のとき、CouchDB はトラブルを避ける方法があります。内部構造はフォールト・トレラントで、故障はコントロールされた状況でしか起きず、慎重に処理されます。問題がひとつだけならサーバーシステム全体に影響を及ぼすことなく、そのリクエストの失敗だけで済みます。
CouchDB’s core concepts are simple (yet powerful) and well understood. Operations teams (if you have a team; otherwise, that’s you) do not have to fear random behavior and untraceable errors. If anything should go wrong, you can easily find out what the problem is—but these situations are rare.
CouchDB の中核の考え方はシンプルで(だからこそ強力)、理解しやすいものです。運用チーム(いなければあなた)は、不安定な動作や追跡できないエラーに怯える必要はありません。もし何かがおかしければ簡単に問題を発見することができますが、そんなことはほとんど起きないでしょう。
CouchDB is also designed to handle varying traffic gracefully. For instance, if a website is experiencing a sudden spike in traffic, CouchDB will generally absorb a lot of concurrent requests without falling over. It may take a little more time for each request, but they all get answered. When the spike is over, CouchDB will work with regular speed again.
CouchDBは、変動する負荷をうまく扱うようにも設計されています。たとえば、あなたのWebサイトに急なスパイク負荷が来たら、ふつうのCouchDBは落とすことなく多数のリクエストの負荷を吸収することでしょう。落ちる代わりに、それぞれのリクエストで少しだけ時間を要するようになるだけで、全ての処理を完了します。一時的な負荷が終われば、CouchDBは再び高速に動作します。
The third area of relaxation is growing and shrinking the underlying hardware of your application. This is commonly referred to as scaling. CouchDB enforces a set of limits on the programmer. On first look, CouchDB might seem inflexible, but some features are left out by design for the simple reason that if CouchDB supported them, it would allow a programmer to create applications that couldn’t deal with scaling up or down. We’ll explore the whole matter of scaling CouchDB in Part IV, “Deploying CouchDB”.
三つめのリラックスは、あなたのアプリケーションを支える、増加または減少するハードウェアです。これは主にスケーリングの章でのはなしです。CouchDBはいくつかの制約をプログラマーに課します。まず、CouchDB は柔軟に見えないかもしれませんが、設計をシンプルに保つことによって、プログラマーにスケーラビリティの問題を考えさせなくてよいようにするためです。繰り返しになりますが、スケーリングは、ハードウェアの増加・減少のことです。4章「CouchDBのデプロイ」 で詳細を説明します。
In a nutshell: CouchDB doesn’t let you do things that would get you in trouble later on. This sometimes means you’ll have to unlearn best practices you might have picked up in your current or past work. Chapter 24, Recipes contains a list of common tasks and how to solve them in CouchDB.
簡単にいうと: CouchDB は後であなたを困らせることをしません。つまり、あなたが今もしくは以前の仕事で積み上げてきたベストプラクティスが不要ということです。「レシピ」の章にはよくある一般的なタスクをCouchDBで片付けるための方法が書かれています。
We believe that CouchDB will drastically change the way you build document-based applications. CouchDB combines an intuitive document storage model with a powerful query engine in a way that’s so simple you’ll probably be tempted to ask, “Why has no one built something like this before?”
あなたがドキュメントベースのアプリケーションを構築する方法を、CouchDBは大きく変えてしまうことでしょう。CouchDB は直感的なストレージモデルと、強力なクエリエンジンを組み合わせ、あなたが「なんでこういうものが今までなかったの?」と思うほどにシンプルになっているでしょう。
Django may be built for the Web, but CouchDB is built of the Web. I’ve never seen software that so completely embraces the philosophies behind HTTP. CouchDB makes Django look old-school in the same way that Django makes ASP look outdated.
—Jacob Kaplan-Moss, Django developer
"DjangoはWebのために作られたけど、CouchDBはWebで作られた。HTTPの背景にある哲学を完全に包含したソフトウェアを今まで見たことがなかった。DjangoにくらべてASPが古く見えるように、CouchDBをみていると、Djangoが古く見えてしまうよ"
—Jacob Kaplan-Moss, Django開発者
CouchDB’s design borrows heavily from web architecture and the concepts of resources, methods, and representations. It augments this with powerful ways to query, map, combine, and filter your data. Add fault tolerance, extreme scalability, and incremental replication, and CouchDB defines a sweet spot for document databases.
CouchDBの設計はWebアーキテクチャと、そのリソース、メソッド、表現などの概念を導入しています。これによってCouchDBは、強力なクエリ、マップ、組み合わせ、フィルタなどの手法により、さらに強力になっています。さらに、耐故障性や強力なスケーラビリティ、インクリメンタルなレプリケーションによって、CouchDBはドキュメントデータベースの勘所を全て抑えることができます。
We write software to improve our lives and the lives of others. Usually this involves taking some mundane information—such as contacts, invoices, or receipts—and manipulating it using a computer application. CouchDB is a great fit for common applications like this because it embraces the natural idea of evolving, self-contained documents as the very core of its data model.
私たちがソフトウェアを作るのは、自分たちやみなさんの生活をよりよくするためです。これはふつう何を指すかというと、住所録や、請求書(納品書)、領収書といったありきたりな情報を扱ったり、コンピューターソフトウェアを使ってそれを扱うことです。CouchDBは変化する自己完結したドキュメントをデータモデルの中心に置いているため、こういったふつうのアプリケーションを構築するのに非常に適しています。
An invoice contains all the pertinent information about a single transaction—the seller, the buyer, the date, and a list of the items or services sold. As shown in Figure 1, “Self-contained documents”, there’s no abstract reference on this piece of paper that points to some other piece of paper with the seller’s name and address. Accountants appreciate the simplicity of having everything in one place. And given the choice, programmers appreciate that, too.
請求書では、重要な情報がひとつのトランザクションに全て含まれています:請求者、宛先、日時、販売された物もしくはサービスのリストです。図1にあるように、宛先の名称や住所などが記された他の伝票を参照していることはありません。会計士はこのように、全てが一箇所に書かれていることに感謝するべきです。こんなふうになっていればプログラマーも感謝します。
Figure 1. Self-contained documents
図1 自己完結したドキュメント
Yet using references is exactly how we model our data in a relational database! Each invoice is stored in a table as a row that refers to other rows in other tables—one row for seller information, one for the buyer, one row for each item billed, and more rows still to describe the item details, manufacturer details, and so on and so forth.
つまり、これがまさに我々のデータをRDBMSにモデリングする方法なのです!全ての請求書はひとつのテーブルの行として格納され、他のテーブルの他の行を参照します。ひとつの列は請求元の情報、もうひとつは請求先、ひとつの列は購入・支払された商品、そして生産元など商品の詳細のためのまだまだ多くの列があったりします。
This isn’t meant as a detraction of the relational model, which is widely applicable and extremely useful for a number of reasons. Hopefully, though, it illustrates the point that sometimes your model may not “fit” your data in the way it occurs in the real world.
リレーショナルモデルを非難するつもりではなく、リレーショナルモデルもいろいろな理由から広く応用ができます。しかし、願わくば、あなたのリレーショナルモデルはしばしば、あなたのデータに適しているとは限らないことが分かるでしょうか。
Let’s take a look at the humble contact database to illustrate a different way of modeling data, one that more closely “fits” its real-world counterpart—a pile of business cards. Much like our invoice example, a business card contains all the important information, right there on the cardstock. We call this “self-contained” data, and it’s an important concept in understanding document databases like CouchDB.
こんどは小さなアドレス帳についてみてみましょう。実世界の対象によりフィットするデータモデリングの別の方法を描き出してみましょう。名刺の束です。請求書の例のように、名刺には重要な情報が全て載っており、カード入れに積まれています。これを自己完結したデータとよびます。CouchDBのようなドキュメントデータベースでは重要な概念です。
Most business cards contain roughly the same information—someone’s identity, an affiliation, and some contact information. While the exact form of this information can vary between business cards, the general information being conveyed remains the same, and we’re easily able to recognize it as a business card. In this sense, we can describe a business card as a real-world document.
大抵の場合名刺は、氏名、所属、連絡先、どれも似たような情報を掲載しています。こういった情報のフォーマットは名刺によっていろいろ変わりますが、掲載されている大まかな内容はどれも同じなので、見ればすぐに名刺だとわかります。こういう意味で、名刺は実世界のドキュメントだといえます。
Jan’s business card might contain a phone number but no fax number, whereas J. Chris’s business card contains both a phone and a fax number. Jan does not have to make his lack of a fax machine explicit by writing something as ridiculous as “Fax: None” on the business card. Instead, simply omitting a fax number implies that he doesn’t have one.
ジャンの名刺は電話番号はあるけどFAX番号はない。クリスの名刺は電話番号もFAX番号も載っています。ジャンの場合、名刺に「FAX:空欄」などとヘンなことを明示的に書く必要はありません。代わりに、FAX欄を載せないことで、FAXがないことを暗黙のうちに示すことができます。
We can see that real-world documents of the same type, such as business cards, tend to be very similar in semantics—the sort of information they carry—but can vary hugely in syntax, or how that information is structured. As human beings, we’re naturally comfortable dealing with this kind of variation.
名刺のように同じ形式の実世界のドキュメントは、載っている情報などのセマンティクス上は非常によく似ていますが、情報が表示される構成、つまりシンタックスでは大きく異なってしまいます。
While a traditional relational database requires you to model your data up front, CouchDB’s schema-free design unburdens you with a powerful way to aggregate your data after the fact, just like we do with real-world documents. We’ll look in depth at how to design applications with this underlying storage paradigm.
伝統的なRDBMSではデータを事前に明示的にモデリングする必要がありますが、CouchDBのスキーマフリーな設計は、我々が実世界ドキュメントでやっているような現実に即してあなたのデータを後でまとめる強力な手法で、モデリングに関するあなたの肩の荷を軽くしてくれます。このようなストレージ・パラダイムの上でどのようにアプリケーションを設計していくかをこれから詳しく見ていきましょう。
CouchDB is a storage system useful on its own. You can build many applications with the tools CouchDB gives you. But CouchDB is designed with a bigger picture in mind. Its components can be used as building blocks that solve storage problems in slightly different ways for larger and more complex systems.
CouchDBはそれだけでとても有用なストレージシステムです。CouchDBが提供するツールでいろいろなアプリケーションを構築できます。しかしCouchDBはもっと大きな青写真を持って設計されています。各コンポーネントはより大きくて複雑なシステムの構成要素として使うことができます。ストレージの問題をちょっと違う方法で解決することでしょう。
Whether you need a system that’s crazy fast but isn’t too concerned with reliability (think logging), or one that guarantees storage in two or more physically separated locations for reliability, but you’re willing to take a performance hit, CouchDB lets you build these systems.
あなたの望むシステムが、驚くほど高速だが信頼性についてはそれほど気にしないシステム(ロギングのシステムを考えてみてください)であれ、信頼性のためストレージを2つ以上の物理的に離れた場所にあることを保証するがパフォーマンスの低下については甘受するようなシステムであれ、あなたはCouchDBでそれらのシステムを作ることができます。
There are a multitude of knobs you could turn to make a system work better in one area, but you’ll affect another area when doing so. One example would be the CAP theorem discussed in the next chapter. To give you an idea of other things that affect storage systems, see Figures 2 and 3.
ひとつの領域でシステムがよりよく動作するためのツマミは沢山ありますが、ひとつの領域を変更しようとツマミを操作すると意図しない他の領域も変更されてしまいます。次章で説明するCAP定理がよい例でしょう。ストレージシステムの考え方を図2と図3に示します。
By reducing latency for a given system (and that is true not only for storage systems), you affect concurrency and throughput capabilities.
(ストレージシステム以外でもこれは当てはまるのですが)レイテンシを下げようとすると、並列性とスループットに影響します。

Figure 2. Throughput, latency, or concurrency
図2 スループット、レイテンシ、並列性
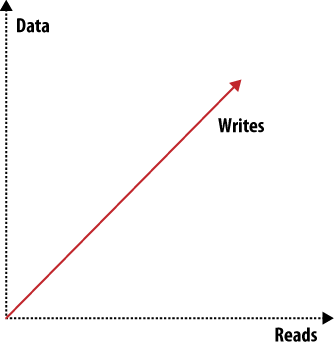
Figure 3. Scaling: read requests, write requests, or data
図3 スケーリング:リード、ライト、データ
When you want to scale out, there are three distinct issues to deal with: scaling read requests, write requests, and data. Orthogonal to all three and to the items shown in Figures 2 and 3 are many more attributes like reliability or simplicity. You can draw many of these graphs that show how different features or attributes pull into different directions and thus shape the system they describe.
スケールアウトさせたい場合、読み込み性能のスケーリング、書き込み性能のスケーリング、データ量の三つの方向があります。これらの三方向と図2と図3で示した観点に直交する観点として、信頼性やシンプルさなどの多くの観点があります。このように、異なった方向性や特徴をグラフに描くことによって、システムの特徴を明らかにすることができます。
CouchDB is very flexible and gives you enough building blocks to create a system shaped to suit your exact problem. That’s not saying that CouchDB can be bent to solve any problem—CouchDB is no silver bullet—but in the area of data storage, it can get you a long way.
CouchDBはとても柔軟であなたの問題を解決するようなシステムの構成要素となりえます。これは、CouchDBはどんな問題でも解けるという意味ではありません - 銀の弾丸ではありませんが、一般的には、データストレージの道のりは長いものです。
CouchDB replication is one of these building blocks. Its fundamental function is to synchronize two or more CouchDB databases. This may sound simple, but the simplicity is key to allowing replication to solve a number of problems: reliably synchronize databases between multiple machines for redundant data storage; distribute data to a cluster of CouchDB instances that share a subset of the total number of requests that hit the cluster (load balancing); and distribute data between physically distant locations, such as one office in New York and another in Tokyo.
CouchDBのレプリケーションはこのような構成要素のひとつです。レプリケーションの根本的な機能は、二つ以上のCouchDBデータベースを同期させることです。簡単に聞こえるかもしれませんが、シンプルだからこそレプリケーションが数多くの問題の解決となっているのです。(1)冗長構成のデータストレージのための複数マシン間でデータベースを信頼できる方法で同期するのです。(2)データをCouchDBクラスタに分散することで、リクエストの総数を分散することができます(ロードバランシング)。(3)データを物理的に異なるロケーションに配置することができます。たとえば、ひとつはニューヨークのオフィスに、もうひとつは東京に、といった具合に。
CouchDB replication uses the same REST API all clients use. HTTP is ubiquitous and well understood. Replication works incrementally; that is, if during replication anything goes wrong, like dropping your network connection, it will pick up where it left off the next time it runs. It also only transfers data that is needed to synchronize databases.
CouchDBのレプリケーションはクライアントが使うものと同じREST APIを使います。HTTPは普遍なのです。レプリケーションはインクリメンタルに実行されます。もしレプリケーション中に何かがおかしくなった場合には、 - 例えばネットワーク切断など - 次回は失敗したところから再開します。データベースの同期に必要なデータだけを転送します。
A core assumption CouchDB makes is that things can go wrong, like network connection troubles, and it is designed for graceful error recovery instead of assuming all will be well. The replication system’s incremental design shows that best. The ideas behind “things that can go wrong” are embodied in the Fallacies of Distributed Computing:
CouchDBの根底にある前提は、物事は失敗するという点です。何もかもが正常であることを期待するのではなく、エラーに対して寛大になり回復を試みます。レプリケーションシステムのインクリメンタルな設計が最適なのです。「物事は故障する」という考え方は Fallacies of Distributed Computing にあります:
Existing tools often try to hide the fact that there is a network and that any or all of the previous conditions don’t exist for a particular system. This usually results in fatal error scenarios when something finally goes wrong. In contrast, CouchDB doesn’t try to hide the network; it just handles errors gracefully and lets you know when actions on your end are required.
既存のツールはネットワークが存在して、上記の条件を隠蔽してしまう場合がしばしばあります。これはふつう、結局何かがおかしくなってしまう致命的なエラーシナリオに至ってしまいます。CouchDBではネットワークを隠蔽せず、エラーを寛大に処理して、あなたがどのような対処をとるべきかを知らせてくれます。
CouchDB takes quite a few lessons learned from the Web, but there is one thing that could be improved about the Web: latency. Whenever you have to wait for an application to respond or a website to render, you almost always wait for a network connection that isn’t as fast as you want it at that point. Waiting a few seconds instead of milliseconds greatly affects user experience and thus user satisfaction.
CouchDBはWebからいくつかの教訓を得ていますが、Webの残念なところがひとつだけあります。それはレイテンシです。あなたは、アプリケーションが反応してウェブサイトを再描画して、そこで待ちたくないけどネットワーク接続を待ってしまいます。ミリ秒のかわりに数秒待つのはユーザエクスペリエンスや顧客満足度に強く影響することでしょう。
What do you do when you are offline? This happens all the time—your DSL or cable provider has issues, or your iPhone, G1, or Blackberry has no bars, and no connectivity means no way to get to your data.
さらに、オフライン時に何をしているか、です。これは常に起こりえます。あなたのDSLまたはケーブルテレビ回線のプロバイダが問題を持っていれば、あなたのiPhoneなどのケータイはアンテナが立ってない状態の場合、自分のデータに一切アクセスできなくなってしまいます。
CouchDB can solve this scenario as well, and this is where scaling is important again. This time it is scaling down. Imagine CouchDB installed on phones and other mobile devices that can synchronize data with centrally hosted CouchDBs when they are on a network. The synchronization is not bound by user interface constraints like subsecond response times. It is easier to tune for high bandwidth and higher latency than for low bandwidth and very low latency. Mobile applications can then use the local CouchDB to fetch data, and since no remote networking is required for that, latency is low by default.
CouchDB はこのシナリオを防ぐことができます - そして、ここでもスケーリングが重要となってきます。今回はスケールダウンです。CouchDBが携帯電話などのモバイル機器にインストールされており、オンラインのときは中央サーバにあるCouchDBと同期できるのです。同期作業は、ユーザーインターフェイスのように一秒以内のレスポンスタイムが要求されることはありません。低帯域・低レイテンシの状況よりも、広帯域・高レイテンシの方がチューニングは容易です。ローカルのCouchDBを利用すれば、ネットワーク接続が不要で、ローカルなのでDBアクセスも低レイテンシで済むため、モバイルアプリケーションを構築するのはとても容易になります。
Can you really use CouchDB on a phone? Erlang, CouchDB’s implementation language has been designed to run on embedded devices magnitudes smaller and less powerful than today’s phones.
携帯電話のCouchDBは可能なのでしょうか? CouchDBの実装言語のErlangは、今日の携帯電話よりも小さな組み込み系デバイスでも動作するように設計されています。
The next chapter further explores the distributed nature of CouchDB. We should have given you enough bites to whet your interest. Let’s go!
次章では、CouchDBの分散構成の機能をさらに探検しましょう。あなたの興味をそそるには十分興味のある内容を既に話してあると思います。行きましょう!