All map functions have a single parameter doc. This is a single document in the database. Our map function checks whether our document has a date and a title attribute—luckily, all of our documents have them—and then calls the built-in emit() function with these two attributes as arguments.
すべてのmap関数は、docという一つのパラメータを引数にとります。これは、データベースの中の一つのドキュメントを示します。先ほどのサンプルのmap関数はドキュメントがdateやtitle属性を持っているかを確認します。(幸運にも、私たちのドキュメントはそれらを持っていました)そして、組み込みのemit()関数を二つの引数と共に呼び出します。
The emit() function always takes two arguments: the first is key, and the second is value. The emit(key, value) function creates an entry in our view result. One more thing: the emit() function can be called multiple times in the map function to create multiple entries in the view results from a single document, but we are not doing that yet.
emit()関数は常に二つの引数を取ります。一つ目はkeyで、二つ目はvalueです。emit(key,value)関数はビューの結果となるエントリーを作ります。もう一つ、emit()関数は、マップ関数の中で複数呼び出すことができます。それにより、一つのドキュメントからビューの結果として複数のエントリーを作成することができます。しかし、まだそれに対しては何もしていません。
CouchDB takes whatever you pass into the emit() function and puts it into a list (see Table 1, “View results”). Each row in that list includes the key and value. More importantly, the list is sorted by key (by doc.date in our case). The most important feature of a view result is that it is sorted by key. We will come back to that over and over again to do neat things. Stay tuned.
CouchDBは、emit()関数に渡す物は何でも取り、リストへ格納します(参照Table 1, “View results”).リストの中の各行は、keyとvalueを含んでいます。更に重要なこととして、リストはkeyによってソートされます(例ではdoc.dateです)。ビューの結果の最も重要な機能は、keyでソートされるということでしょう。私たちはこれを整頓するために、何度も何度も戻ると思いますが、我慢して聞き続けて下さい。
| Key | Value |
|---|---|
"2009/01/15 15:52:20" | "Hello World" |
"2009/01/30 18:04:11" | "Biking" |
"2009/02/17 21:13:39" | "Bought a Cat" |
Table 1. View results
If you read carefully over the last few paragraphs, one part stands out: “When you query your view, CouchDB takes the source code and runs it for you on every document in the database.” If you have a lot of documents, that takes quite a bit of time and you might wonder if it is not horribly inefficient to do this. Yes, it would be, but CouchDB is designed to avoid any extra costs: it only runs through all documents once, when you first query your view. If a document is changed, the map function is only run once, to recompute the keys and values for that single document.
注意深く一つ前の段落を読んでいたらなら、一カ所 "ビューを問い合わせたときに、CouchDBがソースコードを取得し、ビューを定義したデータベースの中のすべてのドキュメントに対して実行されます。"という部分が気になったのではないでしょうか。沢山のドキュメントを保管していた場合、短い時間で結果を得られるものであって、ものすごく効率の悪い物ではないことを望むでしょう。その通りです。しかし、CouchDBは大きなコストとならないようにデザインされています。ビューを初めて呼び出したときに、すべてのドキュメントに対して一度だけ実行します。もし、ドキュメントが変更された場合は、map関数はその一つのドキュメントに対して、keyとvalueを再計算するため一度だけ実行されます。
The view result is stored in a B-tree, just like the structure that is responsible for holding your documents. View B-trees are stored in their own file, so that for high-performance CouchDB usage, you can keep views on their own disk. The B-tree provides very fast lookups of rows by key, as well as efficient streaming of rows in a key range. In our example, a single view can answer all questions that involve time: “Give me all the blog posts from last week” or “last month” or “this year.” Pretty neat. Read more about how CouchDB’s B-trees work in Appendix F, The Power of B-trees.
ビューの結果はB-tree内に保管されており、それはドキュメントを保管するための構造です。CouchDBの利用の最適化のため、ビューのB-treeはそれら自身のファイルに保管されており、それら自身のディスクにビューを保管できます。B-treeはkeyでの非常に高速な行の検索を可能にします。keyの範囲での連続した行にも同じように効果的です。私たちの例では、"先週からのすべてのブログの投稿"や"先月, 昨年"といった、時間に関するすべての質問に一つのビューで答えられます。素晴らしいことです。CouchDBのB-treeの動作についてはAppendix F, The Power of B-treesを参照してください。
When we query our view, we get back a list of all documents sorted by date. Each row also includes the post title so we can construct links to posts. Figure 1 is just a graphical representation of the view result. The actual result is JSON-encoded and contains a little more metadata:
ビューを問い合わせる時、日付でソートされたすべてのドキュメントを取得します。各行はまた、投稿のタイトルも含んでいるため、投稿へのリンクを作ることができます。Figure 1は、ビューの結果をグラフィカルに表したものです。実際の結果はJSONでエンコードされており、もう少しメタデータを含んでいます。
{
"total_rows": 3,
"offset": 0,
"rows": [
{
"key": "2009/01/15 15:52:20",
"id": "hello-world",
"value": "Hello World"
},
{
"key": "2009/02/17 21:13:39",
"id": "bought-a-cat",
"value": "Bought a Cat"
},
{
"key": "2009/01/30 18:04:11",
"id": "biking",
"value": "Biking"
}
]
}
Now, the actual result is not as nicely formatted and doesn’t include any superfluous whitespace or newlines, but this is better for you (and us!) to read and understand. Where does that "id" member in the result rows come from? That wasn’t there before. That’s because we omitted it earlier to avoid confusion. CouchDB automatically includes the document ID of the document that created the entry in the view result. We’ll use this as well when constructing links to the blog post pages.
今、実際の結果はうまく整形されておらず、必要以上の空白や改行を含んでいません。しかし、これはあなた(と私たち!)にとって、読んだり理解するには良い形です。結果の行にある"id"メンバーはどこからきたのでしょうか。前回はありませんでした。それは、混乱を避けるため、省略していたからです。CouchDBはビューの結果にエントリーとして作成されるドキュメントのドキュメントIDを自動的に挿入します。私たちはこれをブログの投稿ページへのリンクを構成する際に利用しています。
Efficient Lookups
効果的な検索
Let’s move on to the second use case for views: “building efficient indexes to find documents by any value or structure that resides in them.” We already explained the efficient indexing, but we skipped a few details. This is a good time to finish this discussion as we are looking at map functions that are a little more complex.
ビューの二つ目の利用例である "あらゆるvalueやそれらに存在する構造から、ドキュメントを検索するために有効なインデックスの構成"に進んでみましょう。私たちは既に効果的なインデックスの作成について説明しましたが、いくつかの詳細については飛ばしていました。もう少し複雑なmap関数を見ていく上での議題を完了させる良い機会です。
First, back to the B-trees! We explained that the B-tree that backs the key-sorted view result is built only once, when you first query a view, and all subsequent queries will just read the B-tree instead of executing the map function for all documents again. What happens, though, when you change a document, add a new one, or delete one? Easy: CouchDB is smart enough to find the rows in the view result that were created by a specific document. It marks them invalid so that they no longer show up in view results. If the document was deleted, we’re good—the resulting B-tree reflects the state of the database. If a document got updated, the new document is run through the map function and the resulting new lines are inserted into the B-tree at the correct spots. New documents are handled in the same way. Appendix F, The Power of B-trees demonstrates that a B-tree is a very efficient data structure for our needs, and the crash-only design of CouchDB databases is carried over to the view indexes as well.
まず、B-treeに戻ります!keyが保管されるビュー結果が、初めてのビューに対する問い合わせのとき一度だけ作られることや、後続の問い合わせが、すべてのドキュメントに対してもう一度map関数を実行する代わりにB-Treeを読み込んでいることに関して、B-treeが支えていることを説明しました。ドキュメントを変更したとき、新しく作ったとき、削除した時に、何が起きているのでしょうか。簡単です、CouchDBは特定のドキュメントによって作られたビューの結果の行を見つけることについて十分にスマートです。CouchDBは、invalidとしてマークするため、もはやビューの結果に現れることはありません。もしドキュメントが削除されたら、B-treeの結果はデータベースの状態を反映します。もしドキュメントが更新されたら、新しいドキュメントがmap関数で実行され、新しい結果の行をB-treeの的確な位置に挿入します。新しいドキュメントも同じように扱われます。 Appendix F, The Power of B-treesはB-treeが私たちに必要なデータ構造としてとても効果的であることや、CouchDBのデータベースが良くビューのインデックスを持ち越されるようなcrash-onlyデザインにも効果的であることを実証しています。
To add one more point to the efficiency discussion: usually multiple documents are updated between view queries. The mechanism explained in the previous paragraph gets applied to all changes in the database since the last time the view was queried in a batch operation, which makes things even faster and is generally a better use of your resources.
もう一つの有効的な議題を加えておきます。通常、複数のドキュメントはビューの複数の要求の間で更新されます。前の段落で説明した構造は、バッチ処理で最後にビューが問い合わせられた時からデータベースでのすべての変更に適用されます。これは幾分かの高速化とリソースの有効利用を作り出します。
Find One
一つを探す
On to more complex map functions. We said “find documents by any value or structure that resides in them.” We already explained how to extract a value by which to sort a list of views (our date field). The same mechanism is used for fast lookups. The URI to query to get a view’s result is /database/_design/designdocname/_view/viewname. This gives you a list of all rows in the view. We have only three documents, so things are small, but with thousands of documents, this can get long. You can add view parameters to the URI to constrain the result set. Say we know the date of a blog post. To find a single document, we would use /blog/_design/docs/_view/by_date?key="2009/01/30 18:04:11" to get the “Biking” blog post. Remember that you can place whatever you like in the key parameter to the emit() function. Whatever you put in there, we can now use to look up exactly—and fast.
もう少し複雑なmap関数に進みます。私たちはドキュメントに含まれる値や構造からドキュメントを見つけると言いました。ビューのリストを並び替えるために値をどうやって展開するか説明しました(私たちの例ではdateを用いました)。同じ仕組みが早い検索のために使われています。ビューの結果を得るための問い合わせのURIは/database/_design/designdocname/_view/viewnameです。これはビューとして全ての行のリストを返します。私たちは3つしかドキュメントを用意していませんでしたが、ドキュメントが数千もある場合は、沢山の結果を得ることができます。結果の集まりを絞り込むためにURIにビューパラメータを追加できます。ブログの投稿の日付を知っていたとします。その一つのドキュメントを探すため、/blog/_design/docs/_view/by_date?key="2009/01/30 18:04:11"を使い"Biking"というブログの投稿を得ることができます。覚えていてください、emit()関数へkeyパラメータとして渡したものであれば何でも渡すことが出来ます。
Note that in the case where multiple rows have the same key (perhaps we design a view where the key is the name of the post’s author), key queries can return more than one row.
同じキーを持った行が複数存在している場合(たとえば、キーをブログのポストの著者としてビューをデザイン)、キーの要求は1行よりも多く返すことになります。
Find Many
多くを探す
We talked about “getting all posts for last month.” If it’s February now, this is as easy as /blog/_design/docs/_view/by_date?startkey="2010/01/01 00:00:00"&endkey="2010/02/00 00:00:00". The startkey and endkey parameters specify an inclusive range on which we can search.
"先月のすべてのポストを取得すること"について述べます。もし、今が2月であれば、これは/blog/_design/docs/_view/by_date?startkey="2010/01/01 00:00:00"&endkey="2010/02/00 00:00:00"と同じ意味です。startkeyとendkeyパラメータは検索の出来る範囲を指定します。
To make things a little nicer and to prepare for a future example, we are going to change the format of our date field. Instead of a string, we are going to use an array, where individual members are part of a timestamp in decreasing significance. This sounds fancy, but it is rather easy. Instead of:
より良くするためと次のサンプルのための準備として、データフィールドのフォーマットを変更します。文字列の替わりに、個別の値がタイムスタンプの一部となっている配列を使います。これはとても変に思えますが、とても簡単です。
{
"date": "2009/01/31 00:00:00"
}
we use:
"date": [2009, 1, 31, 0, 0, 0]
Our map function does not have to change for this, but our view result looks a little different. See Table 2, “New view results”.
私たちのmap関数はこのために変更する必要はありません。しかしビューの結果は少し異なります。a href="#table/2">Table 2, “New view results”を見てください。
| Key | Value |
|---|---|
[2009, 1, 15, 15, 52, 20] | "Hello World" |
[2009, 2, 17, 21, 13, 39] | "Biking" |
[2009, 1, 30, 18, 4, 11] | "Bought a Cat" |
Table 2. New view results
And our queries change to /blog/_design/docs/_view/by_date?key=[2009, 1, 1, 0, 0, 0] and /blog/_design/docs/_view/by_date?key=[2009, 01, 31, 0, 0, 0]. For all you care, this is just a change in syntax, not meaning. But it shows you the power of views. Not only can you construct an index with scalar values like strings and integers, you can also use JSON structures as keys for your views. Say we tag our documents with a list of tags and want to see all tags, but we don’t care for documents that have not been tagged.
そして、問い合わせ方法も/blog/_design/docs/_view/by_date?key=[2009, 1, 1, 0, 0, 0]や/blog/_design/docs/_view/by_date?key=[2009, 01, 31, 0, 0, 0]に変更になります。気にすることはありません、文法が変わるだけです。しかし、これはビューのすごさを示しています。インデックスに用いれるのが文字列や数値といったスカラーの値だけでなく、JSONの構造を持った値をビューのキーとして使うことができます。私たちはタグのリストでドキュメントをタグ付けしています。すべてのタグを確認したいという時、タグ付けされていないドキュメントについて扱わないようにしています。
{
...
tags: ["cool", "freak", "plankton"],
...
}
{
...
tags: [],
...
}
function(doc) {
if(doc.tags.length > 0) {
for(var idx in doc.tags) {
emit(doc.tags[idx], null);
}
}
}
This shows a few new things. You can have conditions on structure (if(doc.tags.length > 0)) instead of just values. This is also an example of how a map function calls emit() multiple times per document. And finally, you can pass null instead of a value to the value parameter. The same is true for the key parameter. We’ll see in a bit how that is useful.
この例ではいくつか新しいことを示しています。値を直接使う代わりに構造の状態を使うことができます(if(doc.tags.length > 0))。これはまた、どのようにemit()を一つのドキュメントで複数回呼ぶかのmap関数の例でもあります。そして最後に、valueパラメータへの値の代わりにnullを渡すことができます。keyパラメータにも使えます。それが普通であることを目の当たりにするでしょう。
Reversed Results
予約された結果
To retrieve view results in reverse order, use the descending=true query parameter. If you are using a startkey parameter, you will find that CouchDB returns different rows or no rows at all. What’s up with that?
逆順でビューの結果を収集したい時、descending=trueクエリパラメータを使えます。もし、startkeyパラメータを使っている場合、CouchDBは異なる行を戻すか、何も行が無いように動作するでしょう。これはどうゆうことでしょうか?
It’s pretty easy to understand when you see how view query options work under the hood. A view is stored in a tree structure for fast lookups. Whenever you query a view, this is how CouchDB operates:
あなたがどのようにビュークエリのオプションが特性のもとで動作するかを見ることで、理解するととても簡単です。
- Starts reading at the top, or at the position that
startkeyspecifies, if present. - もし存在していれば、先頭または
startkeyで指定している場所をを読み始めます。 - Returns one row at a time until the end or until it hits
endkey, if present. - もし存在していれば、最後までまたは
endkeyに行き着くまで一度に一行ずつ戻します。
If you specify descending=true, the reading direction is reversed, not the sort order of the rows in the view. In addition, the same two-step procedure is followed.
もし、descending=trueを指定する場合、読み込みの方向が逆転され、ビューにおける行のソートをしません。加えて、同じ2ステップの操作は以下の通りです。
Say you have a view result that looks like this:
| Key | Value |
|---|---|
0 | "foo" |
1 | "bar" |
2 | "baz" |
Here are potential query options: ?startkey=1&descending=true. What will CouchDB do? See #1 above: it jumps to startkey, which is the row with the key 1, and starts reading backward until it hits the end of the view. So the particular result would be:
ここには潜在的なクエリオプションの?startkey=1&descending=trueがあります。CouchDBは何をするのでしょうか?上の#1を見てください。startkeyはkeyが1となる行へ移動します。そして、ビューの終わりがくるまで後ろ向きに読み込みを開始します。それによって得られる結果は以下です。
| Key | Value |
|---|---|
1 | "bar" |
0 | "foo" |
This is very likely not what you want. To get the rows with the indexes 1 and 2 in reverse order, you need to switch the startkey to endkey: endkey=1&descending=true:
これはあなたが欲しいと思うものではなく、インデックスが1と2の行を逆順として取得するためには、startkeyをendkeyに入れ替えることが必要です。endkey=1&descending=trueとする必要があります。
| Key | Value |
|---|---|
2 | "baz" |
1 | "bar" |
Now that looks a lot better. CouchDB started reading at the bottom of the view and went backward until it hit endkey.
少し良くなったように見えます。CouchDBはビューの底を読み始めて、endkeyに行き着くまで戻っていきます。
The View to Get Comments for Posts
投稿に対するコメントを得るためのビュー
We use an array key here to support the group_level reduce query parameter. CouchDB’s views are stored in the B-tree file structure (which will be described in more detail later on). Because of the way B-trees are structured, we can cache the intermediate reduce results in the non-leaf nodes of the tree, so reduce queries can be computed along arbitrary key ranges in logarithmic time. See Figure 1, “Comments map function”.
ここでは、group_levelというreduceのクエリパラメータを利用するために配列のキーを使います。CouchDBのビューはB-treeのファイル構造に保管されています(これについてはまた後で詳しく述べます)。B-treeが構造化されているため、treeの葉ではないノードで中間reduceの結果をキャッシュすることができます。そのため、reduceの問い合わせは、対数時間内で任意のキーの範囲で算出されます。
In the blog app, we use group_level reduce queries to compute the count of comments both on a per-post and total basis, achieved by querying the same view index with different methods. With some array keys, and assuming each key has the value 1:
ブログのアプリケーションの中で、異なる方法で同じビューインデックスを問い合わせることで得られる投稿毎や全体でのコメントの数を算出するために私たちはgroup_levelをreduceの問い合わせで使います。以下のような同じ配列のキーで、それぞれのキーが値1となっていると仮定します。
["a","b","c"] ["a","b","e"] ["a","c","m"] ["b","a","c"] ["b","a","g"]
the reduce view:
reduceビューを以下のように仮定します。
function(keys, values, rereduce) {
return sum(values)
}
returns the total number of rows between the start and end key. So with startkey=["a","b"]&endkey=["b"] (which includes the first three of the above keys) the result would equal 3. The effect is to count rows. If you’d like to count rows without depending on the row value, you can switch on the rereduce parameter:
開始と終了のキーまでの間で得られる行の合計数が返されます。たとえばstartkey=["a","b"]&endkey=["b"](上記のキーのはじめの三つを対象としている)の結果は3となります。行数をカウントすることが目的です。もし、行の値に依存することなく行数を数えたいなら、rereduceパラメータに渡すことができます。
function(keys, values, rereduce) {
if (rereduce) {
return sum(values);
} else {
return values.length;
}
}

Figure 1. Comments map function
This is the reduce view used by the example app to count comments, while utilizing the map to output the comments, which are more useful than just 1 over and over. It pays to spend some time playing around with map and reduce functions. Futon is OK for this, but it doesn’t give full access to all the query parameters. Writing your own test code for views in your language of choice is a great way to explore the nuances and capabilities of CouchDB’s incremental MapReduce system.
これは、コメントを出力するmapに対してコメント数を数えるためにサンプルのアプリケーションで使われているreduceビューで、何度も使います。mapとreduce関数まわりの動作を何度か使います。Futonはこれに対していい選択です。しかし、すべてのクエリパラメータを使用することができません。あなたが好きな言語で、viewのテストコードを記述することはCouchDBのインクリメンタルなMapReduceシステムのニュアンスや機能知るためのよい方法です。
Anyway, with a group_level query, you’re basically running a series of reduce range queries: one for each group that shows up at the level you query. Let’s reprint the key list from earlier, grouped at level 1:
いずれの場合も、group_levelクエリを利用することで、指定したレベルでのグループに対する一連のreduceの範囲問い合わせを実行します。それでは、レベルを1とした場合のグループを、前の例に適用してキーのリストを書いてみましょう。
["a"] 3 ["b"] 2
And at group_level=2:
group_level=2の場合はこのようになります。
["a","b"] 2 ["a","c"] 1 ["b","a"] 2
Using the parameter group=true makes it behave as though it were group_level=Exact, so in the case of our current example, it would give the number 1 for each key, as there are no exactly duplicated keys.
group=trueパラメータは、group_level=Exactと同じ振る舞いをします。よって現在のサンプルの場合で考えると、厳密に重複するキーは存在しないことになり、キーそれぞれに1を設定します。
Reduce/Rereduce
We briefly talked about the rereduce parameter to your reduce function. We’ll explain what’s up with it in this section. By now, you should have learned that your view result is stored in B-tree index structure for efficiency. The existence and use of the rereduce parameter is tightly coupled to how the B-tree index works.
reduce関数でのrereduceパラメータについて簡潔に紹介しました。このセクションではそれが何なのか説明します。さて、ビューの結果が能率のためにB-treeのインデックス構造で保管されていることを思い出して下さい。rereduceパラメータの存在と利用はB-treeのインデックスの動作と密接に関連しています。
Consider the map result shown in Example 1, “Example view result (mmm, food)”.
mapの結果がExample 1, “Example view result (mmm, food)”で表されているものとします。
"afrikan", 1 "afrikan", 1 "chinese", 1 "chinese", 1 "chinese", 1 "chinese", 1 "french", 1 "italian", 1 "italian", 1 "spanish", 1 "vietnamese", 1 "vietnamese", 1
Example 1. Example view result (mmm, food)
When we want to find out how many dishes there are per origin, we can reuse the simple reduce function shown earlier:
それぞれの種類毎にどのくらい必要かを探したい場合、前に使った単純なreduce関数を再度使うことができます。
function(keys, values, rereduce) {
return sum(values);
}
Figure 2, “The B-tree index” shows a simplified version of what the B-tree index looks like. We abbreviated the key strings.
Figure 2, “The B-tree index”はB-treeのインデックスがどのように見えるかを簡潔に表したものです。キーの文字列は省略しています。
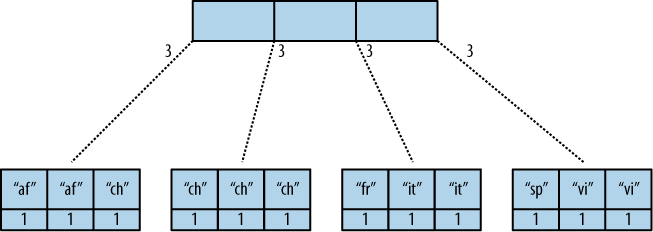
Figure 2. The B-tree index
The view result is what computer science grads call a “pre-order” walk through the tree. We look at each element in each node starting from the left. Whenever we see that there is a subnode to descend into, we descend and start reading the elements in that subnode. When we have walked through the entire tree, we’re done.
ビューの結果はいわゆるコンピュータサイエンスでいう"プリオーダー"で木を巡回します。左側の枝の要素から見始めます。その下に枝があるような要素を見る場合は、下に下がりその枝の要素を読み始めます。木全体を巡回しおわったら完了です。
You can see that CouchDB stores both keys and values inside each leaf node. In our case, it is simply always 1, but you might have a value where you count other results and then all rows have a different value. What’s important is that CouchDB runs all elements that are within a node into the reduce function (setting the rereduce parameter to false) and stores the result inside the parent node along with the edge to the subnode. In our case, each edge has a 3 representing the reduce value for the node it points to.
CouchDBがキーと値両方をそれぞれの葉に持っていることが分かります。私たちのケースの場合、それは単純に常に1です。しかし、あなたの場合は他の結果をカウントした値を持っていて、すべての行が異なる値になっているかもしれません。重要なことは、CouchDBはreduce関数(rereduceパラメータをfalseとして設定している)へ入ってくるノードのすべての要素を実行し、結果をサブノードの節にある親ノードへ保管します。私たちのケースでは、それぞれの節は、その節が持つノードのreduceの値を代表して3を持っています。
In reality, nodes have more than 1,600 elements in them. CouchDB computes the result for all the elements in multiple iterations over the elements in a single node, not all at once (which would be disastrous for memory consumption).
実際には、ノードは1600以上もの要素を持っています。CouchDBは一つのノードの要素に対する複数の繰り返しの中でのすべての要素の結果を計算します。一度にすべてを実行しません。(一度に実行するとメモリ消費の問題になるでしょう)
Now let’s see what happens when we run a query. We want to know how many "chinese" entries we have. The query option is simple: ?key="chinese". See Figure 3, “The B-tree index reduce result”.
では、問い合わせを実行したときに何が起きるか見てみましょう。私たちが持っている結果から"chinese"がどれくらいあるか知りたいとします。問い合わせのオプションは単純に?key="chinese"です。Figure 3, “The B-tree index reduce result”を見て下さい。
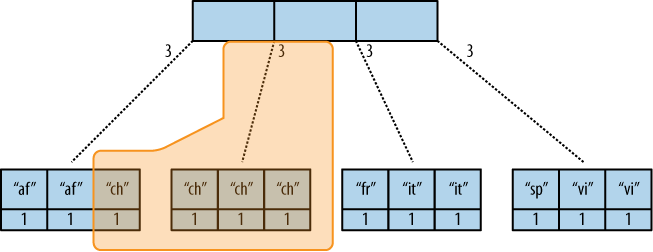
Figure 3. The B-tree index reduce result
CouchDB detects that all values in the subnode include the "chinese" key. It concludes that it can take just the 3 value associated with that node to compute the final result. It then finds the node left to it and sees that it’s a node with keys outside the requested range (key= requests a range where the beginning and the end are the same value). It concludes that it has to use the "chinese" element’s value and the other node’s value and run them through the reduce function with the rereduce parameter set to true.
CouchDBは"chinese"を含むサブノードにあるすべての値を検出します。それは、3を最終結果を計算するためのノードに関連する値として取ることができることを意味しています。それから、ノードの左にそれを探しに行き、要求された範囲(key=は開始と終わりが同じあたいであるような範囲を要求します)の外のキーを持つノードであるかを見ます。そして、"chinese"要素の値や他のノードの値を利用し、reduce関数にrereduceパラメータをtrueに設定して実行します。
The reduce function effectively calculates 3 + 1 on query time and returns the desired result. Example 2, “The result is 4” shows some pseudocode that shows the last invocation of the reduce function with actual values.
reduce関数は要求時間で、効率よく3 + 1を計算します。そして、望んだ結果を返します。Example 2, “The result is 4”は擬似的なコードで、reduce関数の実際の値での最後の引数を示しています。
function(null, [3, 1], true) {
return sum([3, 1]);
}
Example 2. The result is 4
Now, we said your reduce function must actually reduce your values. If you see the B-tree, it should become obvious what happens when you don’t reduce your values. Consider the following map result and reduce function. This time we want to get a list of all the unique labels in our view:
reduce関数は実際に値を集約しなければいけないと言いました。もし、B-treeを見たいなら、値を集約しないときに起こる結果で明白になるでしょう。以下のmapの結果とreduce関数を考えて下さい。ここでは、ビューとしてユニークなラベルの一覧を取得したいとします。
"abc", "afrikan" "cef", "afrikan" "fhi", "chinese" "hkl", "chinese" "ino", "chinese" "lqr", "chinese" "mtu", "french" "owx", "italian" "qza", "italian" "tdx", "spanish" "xfg", "vietnamese" "zul", "vietnamese"
We don’t care for the key here and only list all the labels we have. Our reduce function removes duplicates; see Example 3, “Don’t use this, it’s an example broken on purpose”.
ここではキーは気にせずにすべてのラベルの一覧だけ気にします。reduce関数では重複を削除します。Example 3, “Don’t use this, it’s an example broken on purpose”を見て下さい。
function(keys, values, rereduce) {
var unique_labels = {};
values.forEach(function(label) {
if(!unique_labels[label]) {
unique_labels[label] = true;
}
});
return unique_labels;
}
Example 3. Don’t use this, it’s an example broken on purpose
This translates to Figure 4, “An overflowing reduce index”.
これはFigure 4, “An overflowing reduce index”に変換します。
We hope you get the picture. The way the B-tree storage works means that if you don’t actually reduce your data in the reduce function, you end up having CouchDB copy huge amounts of data around that grow linearly, if not faster with the number of rows in your view.
概要をつかめることを願っています。B-tree領域は、もし実際にreduce関数でデータを集約しない場合、CouchDBは線形的に増える大量のデータをコピーして終わることになります。
CouchDB will be able to compute the final result, but only for views with a few rows. Anything larger will experience a ridiculously slow view build time. To help with that, CouchDB since version 0.10.0 will throw an error if your reduce function does not reduce its input values.
CouchDBは最終的な結果を計算することができますが、いくつかの行のビューだけを計算します。大量な場合は、ビューの作成にとてつもなく時間がかかることになります。これを助けるために、0.10.0以降のCouchDBでは、reduce関数が入力値を集約しない場合にエラーを返します。
See Chapter 21, View Cookbook for SQL Jockeys for an example of how to compute unique lists with views.
Chapter 21, View Cookbook for SQL Jockeysはビューでユニークなリストをどう生成するかの例です。
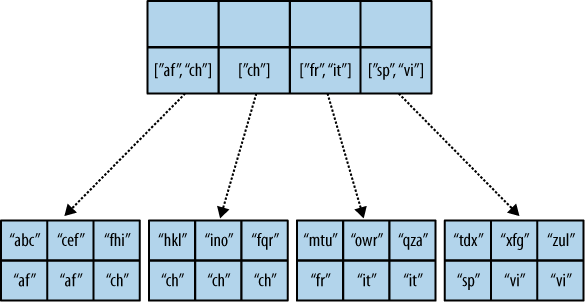
Figure 4. An overflowing reduce index
Lessons Learned
おさらい
- If you don’t use the key field in the map function, you are probably doing it wrong.
- もしmap関数でキーを使わないなら、多分それは間違っています。
- If you are trying to make a list of values unique in the reduce functions, you are probably doing it wrong.
- もしreduce関数でユニークな値のリストを作成することを試みているなら、多分それは間違っています。
- If you don’t reduce your values to a single scalar value or a small fixed-sized object or array with a fixed number of scalar values of small sizes, you are probably doing it wrong.
- もし一つのスカラ値や小さなサイズのオブジェクト、小さなサイズのスカラ値の配列の値をreduceしないなら、多分それは間違っています。
Wrapping Up
まとめ
Map functions are side effect–free functions that take a document as argument and emit key/value pairs. CouchDB stores the emitted rows by constructing a sorted B-tree index, so row lookups by key, as well as streaming operations across a range of rows, can be accomplished in a small memory and processing footprint, while writes avoid seeks. Generating a view takes O(N), where N is the total number of rows in the view. However, querying a view is very quick, as the B-tree remains shallow even when it contains many, many keys.
Map関数は引数としてのドキュメントやkey/valueのペアの出力を取る副作用の無い関数です。CouchDBはB-treeのインデックスで並び替えて構成し、出力された行を保管します。そして行の範囲に対しての操作のような行の参照にキーを利用します。これにより、探し出すこを避けて書き込むことで少ないメモリと処理で完了できます。ビューの生成はO(N)オーダーで、Nはビューの全体の行数です。しかし、B-treeは沢山のキーを含んでいるときでも依然として浅いため、ビューの要求はとても早いです。
Reduce functions operate on the sorted rows emitted by map view functions. CouchDB’s reduce functionality takes advantage of one of the fundamental properties of B-tree indexes: for every leaf node (a sorted row), there is a chain of internal nodes reaching back to the root. Each leaf node in the B-tree carries a few rows (on the order of tens, depending on row size), and each internal node may link to a few leaf nodes or other internal nodes.
Reduce関数はmap関数が出力され並び替えられた行を操作します。CouchDBのreduceの機能は基本的なB-treeインデックスの属性の一つとしての特性を持っています。B-treeでのそれぞれの葉ノード(昇順の行)で、根に戻るための内部的なノードの繋がりがあります。B-treeの葉ノードはいくつかの行を持っています(10のオーダーで、行のサイズに依存します)、そして、各中間ノードはいくつかの葉ノードや他の中間ノードに繋がっています。
The reduce function is run on every node in the tree in order to calculate the final reduce value. The end result is a reduce function that can be incrementally updated upon changes to the map function, while recalculating the reduction values for a minimum number of nodes. The initial reduction is calculated once per each node (inner and leaf) in the tree.
reduce関数は、最終的なreduceの値を計算するための木のすべてのノードで動作します。最後の結果は増加的にアップデート可能なreduce関数で、ノードの最小数に対して換算値を再計算しながら、map関数を変更します。最初の換算はtreeの各ノード(中間や葉)に対し一度計算されます。
When run on leaf nodes (which contain actual map rows), the reduce function’s third parameter, rereduce, is false. The arguments in this case are the keys and values as output by the map function. The function has a single returned reduction value, which is stored on the inner node that a working set of leaf nodes have in common, and is used as a cache in future reduce calculations.
葉ノード(実際のmapの行を含む)で動作するとき、reduce関数の三つ目のパラメータであるrereduceはfalseになります。この場合の引数はmap関数によって出力されたキーと値です。共通した葉ノードの集まりで今後のreduceの計算でキャッシュとして利用される中間ノードに保管された換算値を一つ戻します。
When the reduce function is run on inner nodes, the rereduce flag is true. This allows the function to account for the fact that it will be receiving its own prior output. When rereduce is true, the values passed to the function are intermediate reduction values as cached from previous calculations. When the tree is more than two levels deep, the rereduce phase is repeated, consuming chunks of the previous level’s output until the final reduce value is calculated at the root node.
reduce関数が中間ノードで動作する時、rereduceフラグはtrueとなります。これはreduce関数自身が前に出力したものを受け取り、本当に得たいものを明らかにすることを可能にします。rereduceがtrueの時、関数に渡された値は前回の計算からキャッシュされた中間の値となります。木が2レベルより深い場合、rereduceは繰り返され、根ノードでの最終的なreduceの値が計算されるまで一つ前のレベルの結果を消費していきます。
A common mistake new CouchDB users make is attempting to construct complex aggregate values with a reduce function. Full reductions should result in a scalar value, like 5, and not, for instance, a JSON hash with a set of unique keys and the count of each. The problem with this approach is that you’ll end up with a very large final value. The number of unique keys can be nearly as large as the number of total keys, even for a large set. It is fine to combine a few scalar calculations into one reduce function; for instance, to find the total, average, and standard deviation of a set of numbers in a single function.
CouchDBの利用者が作るよくあるミスは複雑に関連のある値をreduce関数で組み立てようとすることです。完全な換算は5のようなスカラ値や例えばユニークなキーやカウントした値の集合のJSONハッシュになるでしょう。このアプローチでの問題は最終的な値がとても大きくなって終わることです。大きな集合であれば、ユニークなキーの数は全体のキーの数と同じくらいになります。いくつかのスカラーの計算を一つのreduce関数に集約することは良い方法です。例えば、一つの関数の中で数値の集まりから合計値、平均値や標準偏差を見つけるためなどです。
If you’re interested in pushing the edge of CouchDB’s incremental reduce functionality, have a look at Google’s paper on Sawzall, which gives examples of some of the more exotic reductions that can be accomplished in a system with similar constraints.
もしCouchDBのインクリメンタルなreduce機能の進んだ利用に興味があるようであれば、Google’s paper on Sawzallを見て下さい。そこれでは似たような状態のシステムで、更なる魅力的な換算の方法の例が取り上げられています。