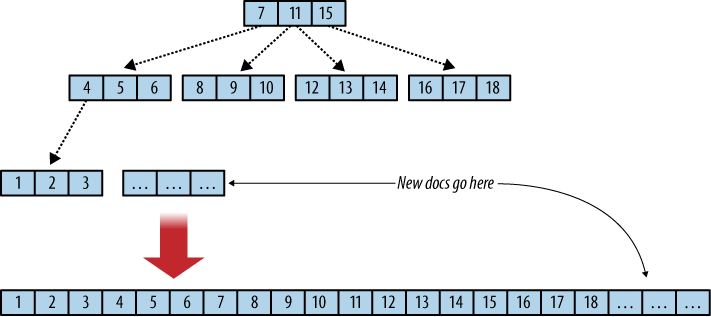
Figure 1. Flat B-tree and append-only
図1. 追記のみのフラットなB木
CouchDB uses a data structure called a B-tree to index its documents and views. We’ll look at B-trees enough to understand the types of queries they support and how they are a good fit for CouchDB.
CouchDBはB木といわれるデータ構造を使って、ドキュメントとビューを管理しています。ここでは、B木を持っているCouchDBにどんなクエリが適しているか、それがいかにCouchDBにマッチしているかを見ていきます。
This is our first foray into CouchDB internals. To use CouchDB, you don’t need to know what’s going on under the hood, but if you understand how CouchDB performs its magic, you’ll be able to pull tricks of your own. Additionally, if you understand the consequences of the ways you are using CouchDB, you will end up with smarter systems.
これが、CouchDBの内部への最初の進出になります。CouchDBを使うだけなら、水面下で何が起きているかを知る必要はありませんが、CouchDBの魔法がどのように演出されているかが分かれば、あなたも手品くらいは使えるようになるかもしれません。加えて、あなたのCouchDBの一連の使い方を理解しておけば、よりスマートにシステムを構築できるでしょう。
If you weren’t looking closely, CouchDB would appear to be a B-tree manager with an HTTP interface.
詳しくみたことがないのなら、CouchDBは、HTTPインターフェースを持ったただのB木管理システムに見えてくることでしょう。
CouchDB is actually using a B+ tree, which is a slight variation of the B-tree that trades a bit of (disk) space for speed. When we say B-tree, we mean CouchDB’s B+ tree.
CouchDBは、B木のちょっとしたバリエーションのB+木を実際には使っていて、 ディスク容量を少し余分に消費する代わりに速度が得られるようになっています。以降、B木と言ったときには、CouchDBのB+木だと思ってください。
A B-tree is an excellent data structure for storing huge amounts of data for fast retrieval. When there are millions and billions of items in a B-tree, that’s when they get fun. B-trees are usually a shallow but wide data structure. While other trees can grow very high, a typical B-tree has a single-digit height, even with millions of entries. This is particularly interesting for CouchDB, where the leaves of the tree are stored on a slow medium such as a hard drive. Accessing any part of the tree for reading or writing requires visiting only a few nodes, which translates to a few head seeks (which are what make a hard drive slow), and because the operating system is likely to cache the upper tree nodes anyway, only the seek to the final leaf node is needed.
B木は巨大なデータを高速に検索するためのとても優れたデータ構造です。百万〜数十億のエントリをB木に楽に格納できます。B木はふつうは浅く広いデータ構造です。他の種類の木構造はとても深くなりがちですが、B木は数百万のエントリを一ケタの深さで保持できます。これはCouchDBのような、ハードディスクのような低速なメディアに格納する際にとても有効です。木構造のどの部分に対して読み込み/書き込みでアクセスしても、数個のノードを経由するだけ(=ハードディスクの遅さの原因であるディスクシークが少し)で済みます(OSが上層のノードの値をキャッシュするため)。
From a practical point of view, B-trees, therefore, guarantee an access time of less than 10 ms even for extremely large datasets.
従って、実用的な観点では、どんなに巨大なデータであっても、B木は10ms以内のアクセス時間を保証するだろう。
—Dr. Rudolf Bayer, inventor of the B-tree
—B木の発明者 ルドルフ・ベイヤー博士
CouchDB’s B-tree implementation is a bit different from the original. While it maintains all of the important properties, it adds Multi-Version Concurrency Control (MVCC) and an append-only design. B-trees are used to store the main database file as well as view indexes. One database is one B-tree, and one view index is one B-tree.
CouchDBのB木の実装は本来のものとは少し異なります。重要な特徴は全て備えていますが、ひとつのデータベースはひとつのB木で、ひとつのビューはB木です。MVCC(Multi Version Concurrency Control)かつ追記のみの設計になっています。B木はメインのデータベースとビューのインデックスで使われています。
MVCC allows concurrent reads and writes without using a locking system. Writes are serialized, allowing only one write operation at any point in time for any single database. Write operations do not block reads, and there can be any number of read operations at any time. Each read operation is guaranteed a consistent view of the database. How this is accomplished is at the core of CouchDB’s storage model.
MVCCを使えば、ロックなしの並行な読み込み・書き込みが実現できます。書き込みは全てシリアライズされ、ひとつのデータベースに同時にはひとつの書き込みだけが許されます。書き込みのオペレーションは読み込みをブロックしませんし、同時にいくらでも読み込みを行うことができます。それぞれの読み込みではデータベースの一貫した状態を見られることが保証されています。これがどのように実現されているかが、CouchDBのストレージモデルの中核になります。
The short answer is that because CouchDB uses append-only files, the B-tree root node must be rewritten every time the file is updated. However, old portions of the file will never change, so every old B-tree root, should you happen to have a pointer to it, will also point to a consistent snapshot of the database.
その端的な理由としては、CouchDBは追記のみのファイルを利用しているので、B木の根ノードは、ファイルが更新される度に毎回書き換えられなければなりません。しかし、ファイルの古い部分は書き換えられないので、B木の全ての古い根ノードは(今は根ノードでなかったとしても)、それはデータベースの過去のスナップショットを見ていることになります。
Early in the book we explained how the MVCC system uses the document’s _rev value to ensure that only one person can change a document version. The B-tree is used to look up the existing _rev value for comparison. By the time a write is accepted, the B-tree can expect it to be an authoritative version.
本書の前半では、MVCCでどのようにドキュメントの _rev の値を使って、ドキュメントへのバージョン更新は同時にただ一人だけということを保証しているかを示しました。既存の _rev の値を比較のために見るためにB木を利用します。書き込みが受け入れられる前に、データが受理できる状態になっていることが期待できます。
Since old versions of documents are not overwritten or deleted when new versions come in, requests that are reading a particular version do not care if new ones are written at the same time. With an often changing document, there could be readers reading three different versions at the same time. Each version was the latest one when a particular client started reading it, but new versions were being written. From the point when a new version is committed, new readers will read the new version while old readers keep reading the old version.
新しいバージョンのドキュメントが作成されるときでも、古いバージョンは上書きされたり削除されたりするわけではないので、特定のバージョンのドキュメントを読み込むリクエストは、新しいバージョンが同時に書き込まれたとしてもそれを気にしません。頻繁に更新されるようなドキュメントでは、3つの異なるバージョンのドキュメントが同時に読み込まれることもあるでしょう。特定のクライアントが読み込みを始めた時、それぞれのバージョンは最新のものになりますが、新しいバージョンは変わらず書き込まれています。新しいバージョンがコミットされた時点から新しく読み込みを始めたクライアントは、新しいバージョンを読み込むようになります。一方、それ以前に読み込みを始めたクライアントは古いバージョンの読み込みを続けます。
In a B-tree, data is kept only in leaf nodes. CouchDB B-trees append data only to the database file that keeps the B-tree on disk and grows only at the end. Add a new document? The file grows at the end. Delete a document? That gets recorded at the end of the file. The consequence is a robust database file. Computers fail for plenty of reasons, such as power loss or failing hardware. Since CouchDB does not overwrite any existing data, it cannot corrupt anything that has been written and committed to disk already. See Figure 1, “Flat B-tree and append-only”.
B木では、データは葉ノードにのみ保存されます。CouchDBのB木はデータをデータベースファイルに追記するだけですから、ディスク上のB木は増える一方です。新しいドキュメントを追加したい? ファイルの最後に追記されます。ドキュメントを消したい? ファイルの最後に削除が記録されます。結果としてデータベースファイルは強靱です。ハードウェア故障や停電などでコンピュータは故障します。CouchDBはどんなデータも上書きしませんから、ディスクに一旦コミットされたものが破壊されることはありません。図1. 追記のみのフラットなB木を参照ください。
Committing is the process of updating the database file to reflect changes. This is done in the file footer, which is the last 4k of the database file. The footer is 2k in size and written twice in succession. First, CouchDB appends any changes to the file and then records the file’s new length in the first database footer. It then force-flushes all changes to disk. It then copies the first footer over to the second 2k of the file and force-flushes again.
コミットする、とはデータベースファイルに更新を反映するという操作です。これはデータベースファイルの *フッタの* 4kに対して行われる操作です。フッタのサイズは2kで、続けて二つ書き込まれます。CouchDBは最初にファイルに対する変更を書き込み、ファイルの新しいサイズを最初のフッタに書き込みます。次にflushを行い、ディスクに全ての変更を反映します。次に最初のフッタを次の2kの部分に書き込んでまたflushします。
Figure 1. Flat B-tree and append-only
図1. 追記のみのフラットなB木
If anywhere in this process a problem occurs—say, power is cut off and CouchDB is restarted later—the database file is in a consistent state and doesn’t need a checkup. CouchDB starts reading the database file backward. When it finds a footer pair, it makes some checks: if the first 2k are corrupt (a footer includes a checksum), CouchDB replaces it with the second footer and all is well. If the second footer is corrupt, CouchDB copies the first 2k over and all is well again. Only once both footers are flushed to disk successfully will CouchDB acknowledge that a write operation was successful. Data is never lost, and data on disk is never corrupted. This design is the reason for CouchDB having no off switch. You just terminate it when you are done.
この過程のどこで問題が起きても、例えば、電源が落ちても、CouchDBが後で起動したときにデータベースのファイルは一貫した状態になり、ファイルの再チェックは不要です。CouchDBはデータベースファイルを逆向きに読んでいきます。フッタのペアが見つかれば、次のポイントをチェックします: 最初の2kが壊れていたら(フッタがチェックサムを持っている)、CouchDBは二番目のフッタを読み込んで差し替えます。二番目のフッタが壊れているときは、CouchDBは最初の2kを読みこむだけで問題ありません。両方のフッタがディスクに正常にflushされたときのみ、CouchDBは書き込み操作が成功したものとします。データが失われることはありませんし、ディスク上のデータは絶対に壊れません。この設計によって、CouchDBは終了のスイッチが不要なのです。完了したら落とすだけでよいのです。
There’s a lot more to say about B-trees in general, and if and how SSDs change the runtime behavior. The Wikipedia article on B-trees is a good starting point for further investigations. Scholarpedia includes notes by Dr. Rudolf Bayer, inventor of the B-tree.
一般的なB木の詳細や、SSDがあったとしたらどのように挙動が変わるか、についてはまだ書き足りていません。より詳しく調べたいなら、WikipediaのB-treesの記事はよい出発点になるでしょう。B木を発明したルドルフ・ベイヤー博士によるScholarpedia(きちんとレビューされたWikipediaのようなもの)のnotesもあります。