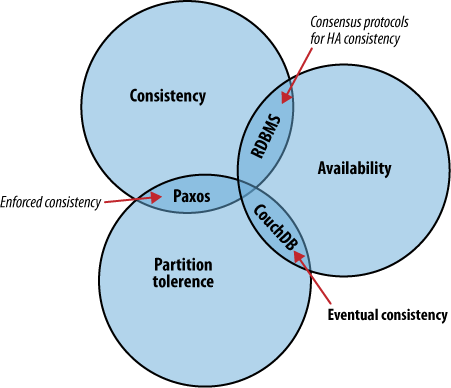
Figure 1. The CAP theorem
Figure 1. CAP理論
In the previous chapter, we saw that CouchDB’s flexibility allows us to evolve our data as our applications grow and change. In this chapter, we’ll explore how working “with the grain” of CouchDB promotes simplicity in our applications and helps us naturally build scalable, distributed systems.
前章では CouchDB の柔軟性が、我々のアプリケーションに拡張と変化を可能にするってことをみてきました。この章では、CouchDBの原料から動作を概観し、システムを自然とスケーラブルな分散システムにする事に役立つ「シンプルさ」について説明します。
A distributed system is a system that operates robustly over a wide network. A particular feature of network computing is that network links can potentially disappear, and there are plenty of strategies for managing this type of network segmentation. CouchDB differs from others by accepting eventual consistency, as opposed to putting absolute consistency ahead of raw availability, like RDBMS or Paxos. What these systems have in common is an awareness that data acts differently when many people are accessing it simultaneously. Their approaches differ when it comes to which aspects of consistency, availability, or partition tolerance they prioritize.
分散システムは広域ネットワーク上で頑健に動作するシステムです。ネットワークコンピューティングの特徴は、ネットワーク接続は切れる可能性があること、ネットワークセグメントを管理する戦略が必要になることです。CouchDBが他の eventual consistency 対応の方法と違うのは、RDBMSやPaxosのようなraw availabilityに対する完全なconsistencyを作るのではないということです。一般的に、多くの人が同時にアクセスするときのデータの動作は異なります。対処の方法は、一貫性(consistency)、可用性(availability)、耐分割性(partition tolerance)について、どこに優先度を置くかによって異なります。
Engineering distributed systems is tricky. Many of the caveats and “gotchas” you will face over time aren’t immediately obvious. We don’t have all the solutions, and CouchDB isn’t a panacea, but when you work with CouchDB’s grain rather than against it, the path of least resistance leads you to naturally scalable applications.
分散システムを扱うのはとてもトリッキーです。やっていくと、たくさんの注意点や「わかったぞ」に出会う事になります。我々は全ての解決策を持っている訳ではありませんし、CouchDBは万能薬(panacea)ではありませんが、CouchDBをよく理解して使えば、自然にスケールするアプリケーションに向けての障害の少ない道を歩むことができるでしょう。
Of course, building a distributed system is only the beginning. A website with a database that is available only half the time is next to worthless. Unfortunately, the traditional relational database approach to consistency makes it very easy for application programmers to rely on global state, global clocks, and other high availability no-nos, without even realizing that they’re doing so. Before examining how CouchDB promotes scalability, we’ll look at the constraints faced by a distributed system. After we’ve seen the problems that arise when parts of your application can’t rely on being in constant contact with each other, we’ll see that CouchDB provides an intuitive and useful way for modeling applications around high availability.
もちろん分散システムの構築は始まったばかりです。1つのデータベースで作られたウェブサイトは半分の時間で作れますが、役立たずになりやすいものです。残念ながら、伝統的なリレーショナルデータベースのアプローチが持つ一貫性(consistency)は、プログラマがグローバルな状態/クロック/高可用性を信頼できるので、うまく動いている事さえ確認できればとても簡単です。CouchDBのスケーラビリティを検証する前に、分散システムが直面する制約についてみておきましょう。そのあと、各パーツがお互いに通信できることを保証できない場合に発生する問題について確認し、CouchDBが高可用アプリケーションのモデリングに関して直感的で便利な方法を提供できることをみていきます。
The CAP theorem describes a few different strategies for distributing application logic across networks. CouchDB’s solution uses replication to propagate application changes across participating nodes. This is a fundamentally different approach from consensus algorithms and relational databases, which operate at different intersections of consistency, availability, and partition tolerance.
CAP理論によって、ネットワークを越える分散アプリケーションロジックの戦略の違いが説明できます。CouchDBでは、参加ノード間でアプリケーションの変化をレプリケーションで伝播(propagate)します。これは、一致アルゴリズム(consensus algorythm)とリレーショナルデータベースとは違うアプローチで 一貫性(consistency)、可用性(availability)、耐分割性(partition tolerance)について、異なる組み合わせを採用している、ということがいえます。
The CAP theorem, shown in Figure 1, “The CAP theorem”, identifies three distinct concerns:
CAP理論は図1に示す3つの領域
Pick two.
このうち2つだけしか同時に実現できないことを示しています。
Figure 1. The CAP theorem
Figure 1. CAP理論
When a system grows large enough that a single database node is unable to handle the load placed on it, a sensible solution is to add more servers. When we add nodes, we have to start thinking about how to partition data between them. Do we have a few databases that share exactly the same data? Do we put different sets of data on different database servers? Do we let only certain database servers write data and let others handle the reads?
システムが単一のデータベースノードに収まらないくらい大きくなったら、サーバを追加するのはいい解決方法です。ノードを追加するときには、データを複数ノードにどのように分割するかを考え始めなければなりません。全く同じデータを複数のデータベースにおさめるのか、それぞれのデータベースサーバに違うデータを入れるか、それとも特定のデータベースに書き込み、他のデータベースは読み込みだけをおこなうようにするのかなどです。
Regardless of which approach we take, the one problem we’ll keep bumping into is that of keeping all these database servers in synchronization. If you write some information to one node, how are you going to make sure that a read request to another database server reflects this newest information? These events might be milliseconds apart. Even with a modest collection of database servers, this problem can become extremely complex.
どのアプローチを取るかに関係なく、我々がハマりつづける1つの問題は、データベースサーバの同期(syncronization)です。1つのノードに情報を書きこんだら、別のサーバからその新しい情報が読み出せる事を保証するにはどうしたらいいのでしょうか?このイベントはミリ秒ごとに起こります。限られた数のデータベースサーバであっても、この問題はきわめて複雑になることがあります。
When it’s absolutely critical that all clients see a consistent view of the database, the users of one node will have to wait for any other nodes to come into agreement before being able to read or write to the database. In this instance, we see that availability takes a backseat to consistency. However, there are situations where availability trumps consistency:
全てのクライアントがデータベースの一致したビュー(consistent view)を参照できる事が絶対必要な場合、あるノードのユーザは他の全てのノードで読み書きが可能にという条件が満たされるまで待たなければなりません。このケースでは、可用性(availability)は一貫性(consistency)より後回しになります。しかし、一貫性(consistency)が可用性(availability)を切り捨てる状況もあります。
Each node in a system should be able to make decisions purely based on local state. If you need to do something under high load with failures occurring and you need to reach agreement, you’re lost. If you’re concerned about scalability, any algorithm that forces you to run agreement will eventually become your bottleneck. Take that as a given.
—Werner Vogels, Amazon CTO and Vice President
システムの各ノードは純粋にローカル状態に従って動作できるようにする必要があります。問題が起こって負荷が高くなった場合でも、なんとかして条件を満たそうとしたときに迷子になります。スケーラビリティを考えると、そういう条件を満たすためのアルゴリズムは、結局ボトルネックになります。あるがままを受け入れるしかないのです。
—Werner Vogels, Amazon CTO and Vice President
If availability is a priority, we can let clients write data to one node of the database without waiting for other nodes to come into agreement. If the database knows how to take care of reconciling these operations between nodes, we achieve a sort of “eventual consistency” in exchange for high availability. This is a surprisingly applicable trade-off for many applications.
可用性が優先される場合、クライアントは、他のノードが条件にいたる前に、そのノードのデータベースに書き込むことができます。もしデータベースがノード間のこういう処理を仲裁する方法を知っている場合、高可用(HA)のかわりに"結果的一致(eventual consistency)"といったものをおすすめします。多くのアプリケーションに驚くほど妥当なトレードオフをもたらします。
Unlike traditional relational databases, where each action performed is necessarily subject to database-wide consistency checks, CouchDB makes it really simple to build applications that sacrifice immediate consistency for the huge performance improvements that come with simple distribution.
伝統的なリレーショナルデータベースと異なり、それぞれの動作が発生するのは、データベース間の一貫性チェックだけになります。CouchDBは、即時の一貫性を犠牲にするかわりに、シンプルな分散による大きなパフォーマンス改善をえるようなアプリケーションの構築を、とても簡単に実現できます。
Before we attempt to understand how CouchDB operates in a cluster, it’s important that we understand the inner workings of a single CouchDB node. The CouchDB API is designed to provide a convenient but thin wrapper around the database core. By taking a closer look at the structure of the database core, we’ll have a better understanding of the API that surrounds it.
クラスタでのCouchDBの動作を理解する前に、単一ノードでの内部動作をしっかり把握しておく事が重要です。CouchDB APIは利便性を提供できるように設計されていますが、データベースコアのまわりにある薄いラッパーです。データベースコアについて詳しくみていく事で、それを取り巻くAPIをより理解できるようになるでしょう。
At the heart of CouchDB is a powerful B-tree storage engine. A B-tree is a sorted data structure that allows for searches, insertions, and deletions in logarithmic time. As Figure 2, “Anatomy of a view request” illustrates, CouchDB uses this B-tree storage engine for all internal data, documents, and views. If we understand one, we will understand them all.
CouchDBの心臓部は強力なB木ストレージエンジンです。B木とは対数時間で検索/追加/削除が可能なソート済みデータ構造です。図2で示すように、CouchDBはこのB-treeストレージエンジンを全ての内部データ、ドキュメント、ビューに使っています。そのうち1つを理解すれば、ほかも理解できます。
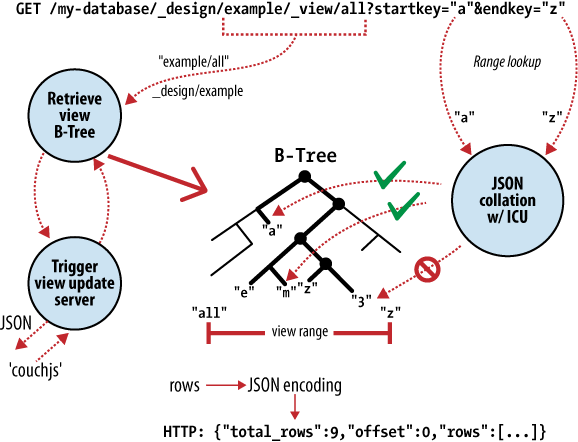
Figure 2. Anatomy of a view request
Figure 2. ビュー要求の構造
CouchDB uses MapReduce to compute the results of a view. MapReduce makes use of two functions, “map” and “reduce,” which are applied to each document in isolation. Being able to isolate these operations means that view computation lends itself to parallel and incremental computation. More important, because these functions produce key/value pairs, CouchDB is able to insert them into the B-tree storage engine, sorted by key. Lookups by key, or key range, are extremely efficient operations with a B-tree, described in big O notation as O(log N) and O(log N + K), respectively.
CouchDB は ビューの結果を計算するのに MapReduce を用いています。MapReduce は2つの関数 "map" と "Reduce" を使い、それぞれ各ドキュメントに独立に適用されます。これらの操作を独立に実行できるようなっているということは、すなわち、ビューの計算は並列かつインクリメンタルな計算でできると言う事を意味しています。さらに重要なのは、これらの関数はkey/valueペアを生成するため、CouchDBはそのままB木ストレージエンジンに追加し、キーでソートする事が可能になっているということです。キーおよびキーのレンジで検索する事は、B木では極めて効率的に処理可能で、O記法でいうと、それぞれO(log n) および O(log N + K)になります。
In CouchDB, we access documents and view results by key or key range. This is a direct mapping to the underlying operations performed on CouchDB’s B-tree storage engine. Along with document inserts and updates, this direct mapping is the reason we describe CouchDB’s API as being a thin wrapper around the database core.
CouchDBでは、ドキュメントとビューへのアクセスはキーとキーのレンジで行います。これはCouchDBのB木ストレージエンジンの処理に直接マッピングされています。文書と挿入と更新について、このように直接マッピングしているということが、CouchDB APIはデータベースコアの薄いラッパだという表現をした理由です。
Being able to access results by key alone is a very important restriction because it allows us to make huge performance gains. As well as the massive speed improvements, we can partition our data over multiple nodes, without affecting our ability to query each node in isolation. BigTable, Hadoop, SimpleDB, and memcached restrict object lookups by key for exactly these reasons.
キーのみで結果にアクセスできるということは非常に重要な制約で、これによって非常に良いパフォーマンスを得られます。大きく高速化すると同時に、各ノードにいちいち問い合わせる必要なしに、データを複数ノードに分割することを可能にします。 BigTable, Hadoop, SimpleDB, memcached はまさにこれらの理由からキーによるオブジェクト検索の制約を設けています。
A table in a relational database is a single data structure. If you want to modify a table—say, update a row—the database system must ensure that nobody else is trying to update that row and that nobody can read from that row while it is being updated. The common way to handle this uses what’s known as a lock. If multiple clients want to access a table, the first client gets the lock, making everybody else wait. When the first client’s request is processed, the next client is given access while everybody else waits, and so on. This serial execution of requests, even when they arrived in parallel, wastes a significant amount of your server’s processing power. Under high load, a relational database can spend more time figuring out who is allowed to do what, and in which order, than it does doing any actual work.
リレーショナルデータベースにおけるテーブルは、単一のデータ構造です。テーブルの修正や列の更新をしたい場合、データベースシステムは、他の誰かがその列を更新してしまわないように、また列の更新中に誰かが読み取ってしまわないようにする必要があります。これを行う一般的な方法はロックとよばれます。複数のクライアントがテーブルにアクセスしたい場合、最初のクライアントがロックを取得し、他のクライアントは待ちます。最初のクライアントの処理がおわったら、次のクライアントは他のクライアントが待ちやそれに類する状態であれば、アクセスできるようになります。このように要求を順番に処理することは、要求が並列で発生する場合ですら行われ、多くのサーバの処理時間を無駄にしてしまいます。高負荷下では、リレーショナルデータベースでは、実際の処理以上に、誰がどの操作を許可されているかを調べるために、より多くの時間が必要になる可能性があります。
Instead of locks, CouchDB uses Multi-Version Concurrency Control (MVCC) to manage concurrent access to the database. Figure 3, “MVCC means no locking” illustrates the differences between MVCC and traditional locking mechanisms. MVCC means that CouchDB can run at full speed, all the time, even under high load. Requests are run in parallel, making excellent use of every last drop of processing power your server has to offer.
CouchDBでは、ロックの代わりに MVCC(Multi Version Concurrency Control) を使ってデータベースアクセスの同時発生を管理しています。図3はMVCCと伝統的なロック機構との違いを視覚化しています。MVCCによって、高い負荷の下でも、CouchDBがフルスピードで動作することができるのです。要求は並列で動作し、サーバの処理能力の最後の一滴まで使い切る事ができます。
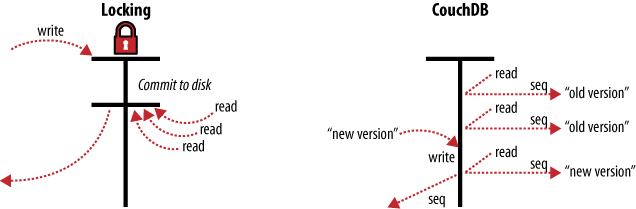
Figure 3. MVCC means no locking
Figure 3. MVCCはロックを行わない
Documents in CouchDB are versioned, much like they would be in a regular version control system such as Subversion. If you want to change a value in a document, you create an entire new version of that document and save it over the old one. After doing this, you end up with two versions of the same document, one old and one new.
CouchDBの文書は、Subversionなどの一般的なバージョン管理システムと同じように、世代管理されます。あるドキュメントの値を変更する場合、旧いバージョンを完全にコピーした新しいバージョンを作成する事になります。この結果、同じドキュメントの2つのバージョン(新旧)が作成されます。
How does this offer an improvement over locks? Consider a set of requests wanting to access a document. The first request reads the document. While this is being processed, a second request changes the document. Since the second request includes a completely new version of the document, CouchDB can simply append it to the database without having to wait for the read request to finish.
この方法がロックより優れているのはなぜでしょうか? それは複数の要求が1つのドキュメントにアクセスしたい場合を考えてみましょう。最初の要求はドキュメントを読み出します。それを処理している間に、2つ目の要求がそのドキュメントを変更します。2つ目の要求は新しいバージョンのドキュメントを作るので、CouchDBは読み出しの完了を待たずに、新しいバージョンをデータベースに追加する事ができます。
When a third request wants to read the same document, CouchDB will point it to the new version that has just been written. During this whole process, the first request could still be reading the original version.
3つ目の要求が同じドキュメントを読み出したい場合、CouchDBは書かれたばかりの新しいバージョンを提示します。これらの処理の間、最初の要求は最初のバージョンを読みっぱなしでも構いません。
A read request will always see the most recent snapshot of your database.
読み出し要求は常に最新のスナップショットを参照します。
As application developers, we have to think about what sort of input we should accept and what we should reject. The expressive power to do this type of validation over complex data within a traditional relational database leaves a lot to be desired. Fortunately, CouchDB provides a powerful way to perform per-document validation from within the database.
アプリケーション開発者としては、どういった入力値を受け入れ、どういった入力値を排除するかについて考える必要があります。伝統的なリレーショナルデータベースにある複雑なデータについて、バリデーションを行う場合の表現力には、まだまだ不満な点があります。幸運な事に、CouchDBはドキュメントごとのバリデーションをデータベース内で行うために強力な方法を提供しています。
CouchDB can validate documents using JavaScript functions similar to those used for MapReduce. Each time you try to modify a document, CouchDB will pass the validation function a copy of the existing document, a copy of the new document, and a collection of additional information, such as user authentication details. The validation function now has the opportunity to approve or deny the update.
CouchDBは、MapReduceでやっているのと同じように、ドキュメントのバリデーションもJavaScriptを使う事ができます。ドキュメントを変更しようとするとき、CouchDBはバリデーション関数を呼び出すことで、その更新を許可するか排除するか決めるタイミングがあります。
By working with the grain and letting CouchDB do this for us, we save ourselves a tremendous amount of CPU cycles that would otherwise have been spent serializing object graphs from SQL, converting them into domain objects, and using those objects to do application-level validation.
CouchDBのこの機能を使う事で、大量のCPUサイクル(SQLからオブジェクトグラフをシリアライズしてドメインオブジェクトにコンバートし、アプリケーションレベルのバリデーションを求めるための)を節約する事ができます。
Maintaining consistency within a single database node is relatively easy for most databases. The real problems start to surface when you try to maintain consistency between multiple database servers. If a client makes a write operation on server A, how do we make sure that this is consistent with server B, or C, or D? For relational databases, this is a very complex problem with entire books devoted to its solution. You could use multi-master, master/slave, partitioning, sharding, write-through caches, and all sorts of other complex techniques.
多くのデータベースにおいてシングルノードの一貫性(consistency)を管理するのは比較的簡単です。本当の問題は複数のデータベースサーバの間の一貫性を管理しようとしたときに表面化しはじめます。あるクライアントがサーバAに書き込みを行ったとき、どうやってサーバB、サーバC、サーバDが一致している事を確認することができるのでしょうか?リレーショナルデータベースでは、ほとんどの本が園か帰結に熱意を注いでいるくらい、とても複雑な問題です。マルチマスタ、マスタ/スレーブ、パーティショニング、共有、ライトスルーキャッシュ、他にもいろいろな複雑なテクニックがあります。
Because CouchDB operations take place within the context of a single document, if you want to use two database nodes, you no longer have to worry about them staying in constant communication. CouchDB achieves eventual consistency between databases by using incremental replication, a process where document changes are periodically copied between servers. We are able to build what’s known as a shared nothing cluster of databases where each node is independent and self-sufficient, leaving no single point of contention across the system.
CouchDBの操作はシングルドキュメントの状態(context)で行われるため、もし2つのデータベースノードを使いたい場合でも、普通の通信しかなく、気にする必要がありません。CouchDBは、データベース間の漸進的レプリケーションを使って、結果的一致(eventual consistency)をとっています。漸進的レプリケーションとは、ドキュメントが変化したら定期的にサーバ間でコピーされるプロセスのことです。データベースのいわゆるシェアードナッシングクラスタとよばれる構成を作る事ができます。各ノードは独立し、自己充足的で、システム全体のシングルポイントになりそうな部分が存在しません。
Need to scale out your CouchDB database cluster? Just throw in another server.
CouchDBデータベースクラスタををスケールアウトする必要はありますか?サーバを追加投入すればいいのです。
As illustrated in Figure 4, “Incremental replication between CouchDB nodes”, with CouchDB’s incremental replication, you can synchronize your data between any two databases however you like and whenever you like. After replication, each database is able to work independently.
図4で示す通り、CouchDBの漸進的レプリケーションによって、データを2つのデータベース間で同期する事ができます。好きな方法で、好きなタイミングで同期できます。レプリケーション後は、各データベースは独立して動作します。
You could use this feature to synchronize database servers within a cluster or between data centers using a job scheduler such as cron, or you could use it to synchronize data with your laptop for offline work as you travel. Each database can be used in the usual fashion, and changes between databases can be synchronized later in both directions.
この機能は、クラスタの中の複数のデータベースサーバを同期するのにも、データセンタ間でジョブスケジューラ(cronなど)による同期にも使えますし、旅行中に仕事するためのラップトップへの同期にも使えます。各データベースはいつもどおり普通に使え、変更はあとで双方向に行う事ができます。
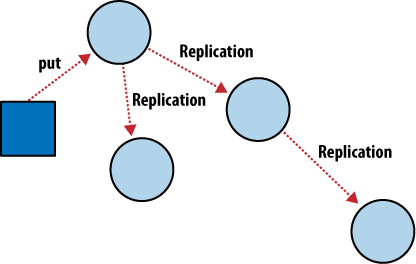
Figure 4. Incremental replication between CouchDB nodes
Figure 4. CouchDBノード間の漸進的レプリケーション
What happens when you change the same document in two different databases and want to synchronize these with each other? CouchDB’s replication system comes with automatic conflict detection and resolution. When CouchDB detects that a document has been changed in both databases, it flags this document as being in conflict, much like they would be in a regular version control system.
異なるデータベース上の同じドキュメントを同時に変更したら何がおこるのでしょうか?CouchDBのレプリケーションシステムは自動的にコンフリクト検出と解消を行います。CouchDBが、あるドキュメントが両方のデータベースで変更された事を検知すると、コンフリクトフラグをたて、一般のバージョンコントロールシステムとほとんど同じような処理をします。
This isn’t as troublesome as it might first sound. When two versions of a document conflict during replication, the winning version is saved as the most recent version in the document’s history. Instead of throwing the losing version away, as you might expect, CouchDB saves this as a previous version in the document’s history, so that you can access it if you need to. This happens automatically and consistently, so both databases will make exactly the same choice.
それは迷惑に聞こえるかもしれませんが、そうでもありません。2つのバージョンのドキュメントがレプリケーション中にコンフリクトした場合、勝ったバージョンはドキュメントのヒストリに保存されます。負けたバージョンは捨てられるのではなく、推測通り、過去のバージョンとしてヒストリに追加されるので、必要になったらアクセスが可能です。これは自動的かつ一貫して行われるため、両方のデータベースが完全に同じ方を(勝ち負けを)選択します。
It is up to you to handle conflicts in a way that makes sense for your application. You can leave the chosen document versions in place, revert to the older version, or try to merge the two versions and save the result.
アプリケーションでコンフリクトをわかるようにする事も可能です。選択されたドキュメントバージョンを捨て、過去バージョンに戻すこともできるし、2つのバージョンをマージして結果を保存する事も可能です。
Greg Borenstein, a friend and coworker, built a small library for converting Songbird playlists to JSON objects and decided to store these in CouchDB as part of a backup application. The completed software uses CouchDB’s MVCC and document revisions to ensure that Songbird playlists are backed up robustly between nodes.
Songbird is a free software media player with an integrated web browser, based on the Mozilla XULRunner platform. Songbird is available for Microsoft Windows, Apple Mac OS X, Solaris, and Linux.
Let’s examine the workflow of the Songbird backup application, first as a user backing up from a single computer, and then using Songbird to synchronize playlists between multiple computers. We’ll see how document revisions turn what could have been a hairy problem into something that just works.
The first time we use this backup application, we feed our playlists to the application and initiate a backup. Each playlist is converted to a JSON object and handed to a CouchDB database. As illustrated in Figure 5, “Backing up to a single database”, CouchDB hands back the document ID and revision of each playlist as it’s saved to the database.
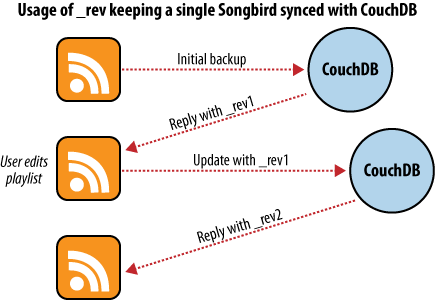
Figure 5. Backing up to a single database
After a few days, we find that our playlists have been updated and we want to back up our changes. After we have fed our playlists to the backup application, it fetches the latest versions from CouchDB, along with the corresponding document revisions. When the application hands back the new playlist document, CouchDB requires that the document revision is included in the request.
CouchDB then makes sure that the document revision handed to it in the request matches the current revision held in the database. Because CouchDB updates the revision with every modification, if these two are out of synchronization it suggests that someone else has made changes to the document between the time we requested it from the database and the time we sent our updates. Making changes to a document after someone else has modified it without first inspecting those changes is usually a bad idea.
Forcing clients to hand back the correct document revision is the heart of CouchDB’s optimistic concurrency.
We have a laptop we want to keep synchronized with our desktop computer. With all our playlists on our desktop, the first step is to “restore from backup” onto our laptop. This is the first time we’ve done this, so afterward our laptop should hold an exact replica of our desktop playlist collection.
After editing our Argentine Tango playlist on our laptop to add a few new songs we’ve purchased, we want to save our changes. The backup application replaces the playlist document in our laptop CouchDB database and a new document revision is generated. A few days later, we remember our new songs and want to copy the playlist across to our desktop computer. As illustrated in Figure 6, “Synchronizing between two databases”, the backup application copies the new document and the new revision to the desktop CouchDB database. Both CouchDB databases now have the same document revision.
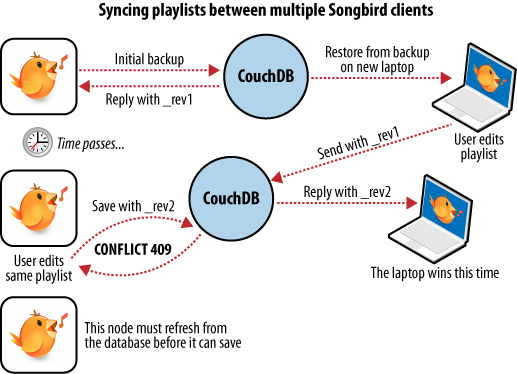
Figure 6. Synchronizing between two databases
Because CouchDB tracks document revisions, it ensures that updates like these will work only if they are based on current information. If we had made modifications to the playlist backups between synchronization, things wouldn’t go as smoothly.
We back up some changes on our laptop and forget to synchronize. A few days later, we’re editing playlists on our desktop computer, make a backup, and want to synchronize this to our laptop. As illustrated in Figure 7, “Synchronization conflicts between two databases”, when our backup application tries to replicate between the two databases, CouchDB sees that the changes being sent from our desktop computer are modifications of out-of-date documents and helpfully informs us that there has been a conflict.
Recovering from this error is easy to accomplish from an application perspective. Just download CouchDB’s version of the playlist and provide an opportunity to merge the changes or save local modifications into a new playlist.
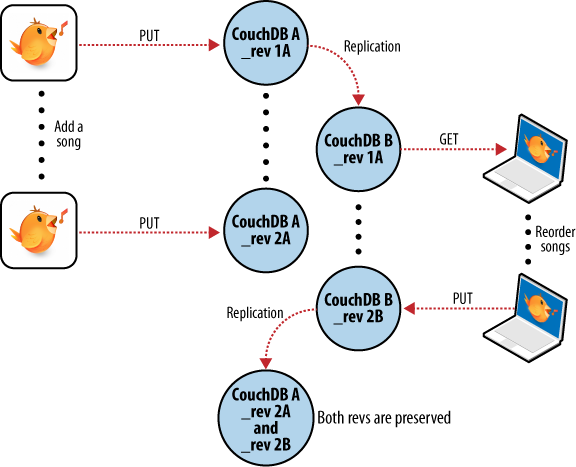
Figure 7. Synchronization conflicts between two databases
CouchDB’s design borrows heavily from web architecture and the lessons learned deploying massively distributed systems on that architecture. By understanding why this architecture works the way it does, and by learning to spot which parts of your application can be easily distributed and which parts cannot, you’ll enhance your ability to design distributed and scalable applications, with CouchDB or without it.
We’ve covered the main issues surrounding CouchDB’s consistency model and hinted at some of the benefits to be had when you work with CouchDB and not against it. But enough theory—let’s get up and running and see what all the fuss is about!