
Figure 1. Conflict management by example: step 1
Figure 1. 衝突管理の例 : step 1
Suppose you are sitting in a coffee shop working on your book. J. Chris comes over and tells you about his new phone. The new phone came with a new number, and you have J. Chris dictate it while you change it using your laptop’s address book application.
あなたは、喫茶店でノートPCを開いて座っているとしましょう。クリスがやってきて、新しいケータイを買ったと言います。新しいケータイは新しい番号になっていて、クリスが新しい番号を口頭で言い、あなたはそれをノートPCのアドレス帳アプリを使って書き取ります [#]_ 。
[#] 訳注:ケータイガラパゴスな日本に住んでいる我々にはちょっと理解できかねるシチュエーションで、「そのままケータイに登録したらええやんけ!」と思わず突っ込みたくなりますが、原文がこうなっていますのでどうかお付き合いください。仮にnew phoneが固定電話だとしたら、ますますワケワカランことですし…。
Luckily, your address book is built on CouchDB, so when you come home, all you need to do to get your home computer up-to-date with J. Chris’s number is replicate your address book from your laptop. Neat, eh? What’s more, CouchDB has a mechanism to maintain continuous replication, so you can keep a whole set of computers in sync with the same data, whenever a network connection is available.
運のいいことに、あなたのアドレス帳はCouchDBでできていました! そうすると、家に帰ったときにあなたがやるべきなのは、家のコンピュータに、ノートPCのデータをレプリケーションするだけで済むのです。楽でしょ?さらにすごいことに、CouchDBは継続的にレプリケーションする仕組みがあるので、好きなときにネットワークに繋いで、全てのコンピュータを同期できます。
Let’s change the scenario a little bit. Since J. Chris didn’t anticipate meeting you at the coffee shop, he also sent you an email with the new number. At the time you weren’t using WiFi because you wanted concentrate on your work, so you didn’t read his email until you got home. But it was a long day and by then you had forgotten that you changed the number in the address book on your laptop. When you read the email at home, you simply copy-and-pasted the number into the address book on your home computer. Now—and here’s the twist—it turns out you entered the wrong number in your laptop’s address book.
少しシナリオを変えてみましょう。クリスは喫茶店で会えなかったのでメールで新しい番号を送ってきたとしましょう。あなたはWiFiを使っていなかったので、仕事に集中していました。あなたは家に帰るまで全くメールを読んでいなかったのですが、長い一日だったので、ノートPCに入っているアドレス帳を更新していたのを忘れていました。あなたはクリスのメールを読んで、あなたの家のコンピュータにクリスの新しい番号をコピー&ペーストで登録しました。ここであなたは、クリスの新しい番号を、間違った番号でノートPCに登録していたとします。
You now have a document in each of the databases that has different information. This situation is called a conflict. Conflicts occur in distributed systems. They are a natural state of your data. How does CouchDB’s replication system deal with conflicts?
ここであなたは、双方のデータベースで矛盾したドキュメントを抱えることになります。このような状況を *衝突* といいます。衝突は分散システムでは必ず発生します。衝突は、あなたのデータにとって自然な状態で、あってはならないわけではありません [#]_ 。CouchDBのレプリケーションシステムは衝突をどのように扱っているのでしょうか? [出版までには電話番号の例え話をきちんとすること]
When you replicate two databases in CouchDB and you have conflicting changes, CouchDB will detect this and will flag the affected document with the special attribute "_conflicts":true. Next, CouchDB determines which of the changes will be stored as the latest revision (remember, documents in CouchDB are versioned). The version that gets picked to be the latest revision is the winning revision. The losing revision gets stored as the previous revision.
ふたつのデータベースをCouchDBでレプリケーションして変更が衝突したとき、CouchDBは衝突を検出して "\_confilicts":trueというフラグを立てます。次にCouchDBは変更のどちらがより新しいものかを決定します(そう、ドキュメントにはバージョンがついているのです)。新しい方が最新のものとして保存され、古い方は過去のリビジョンとして記録されます。
CouchDB does not attempt to merge the conflicting revision. Your application dictates how the merging should be done. The choice of picking the winning revision is arbitrary. In the case of the phone number, there is no way for a computer to decide on the right revision. This is not specific to CouchDB; no other software can do this (ever had your phone’s sync-contacts tool ask you which contact from which source to take?).
CouchDBは、衝突している内容のものをマージしません。マージがどのように行われるべきかはアプリケーションによって決まります。衝突したときに何を最新のリビジョンとすべきかはarbitraryです(TODO:arbitrary?)。電話番号の例であれば、コンピュータには正しいリビジョンを決められません。これは何もCouchDBに特有のことではなくて、他のどんなソフトウェアだろうが起こりえます(まあ、どっちの番号がホントなの?と聞いてくる電話帳もありゃしませんが)。
Replication guarantees that conflicts are detected and that each instance of CouchDB makes the same choice regarding winners and losers, independent of all the other instances. There is no group decision made; instead, a deterministic algorithm determines the order of the conflicting revision. After replication, all instances taking part have the same data. The data set is said to be in a consistent state. If you ask any instance for a document, you will get the same answer regardless which one you ask.
レプリケーションにおいては、衝突が検出されたときどのインスタンスも同じ判断をする(同じものを最新版を選ぶ)ことが保証されています。グループ決定がない代わりに、決定的なアルゴリズムによって最新版を決定します。レプリケーション後、全てのインスタンスは同様のデータを持っています。これは「全てのデータが一貫した状態にある」と言われます。どのインスタンスにドキュメントを問い合わせても同じものを返してくれることでしょう。
Whether or not CouchDB picked the version that your application needs, you need to go and resolve the conflict, just as you need to resolve a conflict in a version control system like Subversion. Simply create a version that you want to be the latest by either picking the latest, or the previous, or both (by merging them) and save it as the now latest revision. Done. Replicate again and your resolution will populate over to all other instances of CouchDB. Your conflict resolving on one node could lead to further conflicts, all of which will need to be addressed, but eventually, you will end up with a conflict-free database on all nodes.
いずれにせよ、CouchDBはアプリケーションが必要とするバージョンを選択しますが、Subversionのようなバージョン管理システムと同様、あなたは衝突を解決する必要があります。単純に、最新の新しい(もしくは古い)バージョンをとりあえず取ってきて使ったり、それらをマージして使ったりすればよいのです。それだけ。もういちどレプリケーションすれば、あなたの決定が他のインスタンスまで伝搬することでしょう。あるサーバ上であなたが衝突を解決することによってまた新しい衝突が発生するかもしれませんが、次第に、データベースの全ての衝突が解決されていくことでしょう。
This is an interesting conflicts scenario in that we helped a BBC build a solution for it that is now in production. The basic setup is this: to guarantee that the company’s website is online 24/7, even in the event of the loss of a data center, it has multiple data centers backing up the website. The “loss” of a data center is a rare occasion, but it can be as simple as a network outage, where the data center is still alive and well but can’t be reached by anyone.
これは、私たちが構築をお手伝いしたイギリスの放送会社のCouchDBの実システムでの面白い衝突のシナリオです。基本的な要件は、会社のウェブサイトは、複数あるデータセンターのひとつくらいが落ちても24/7で動作していること。データセンターが「落ちる」なんてほとんどないと思われますが、いくらデータセンター自体が正常に動いていても、ネットワークの輻輳などでそう見えてしまうことはあります。
The “split brain” scenario is where two (for simplicity’s sake we’ll stick to two) data centers are up and well connected to end users, but the connection between the data centers—which is most likely not the same connection that end users use to talk to the computers in the data center—fails.
スプリット・ブレインのシナリオは(単純のため二つにしておくけど)二つのデータセンターが動作していて正常にエンドユーザと接続されている場合でも、データセンター間の接続が故障し得るのです。エンドユーザとのネットワークとは違う線なのですから。
The inter data center connection is used to keep both centers in sync so that either one can take over for the other in case of a failure. If that link goes down, you end up with two halves of a system that act independently—the split brain.
データセンター間の接続は、双方のセンターがきちんと同期して、片方が故障したときにはフェイルオーバするために必要です。この接続が落ちた場合、二つの不完全なシステムが独立して動作することになります。これがスプリット・ブレインです。
As long as all end users can get to their data, the split brain is not scary. Resolving the split brain situation by bringing up the connection that links the data centers and starting synchronization again is where it gets hairy. Arbitrary conflict resolution, like CouchDB does by default, can lead to unwanted effects on the user’s side. Data could revert to an earlier stage and leave the impression that changes weren’t reliably saved, when in fact they were.
エンドユーザがデータを取得できている間は、スプリット・ブレインはそこまで怖いものではありません。スプリット・ブレインの状況を解決するためには、データセンター間を再び接続して同期を再開すればよいのです。CouchDBがデフォルトで行うような TODO: arbitrary な衝突の解決はユーザサイドに影響します。データは昔の状態のままだったり、変更を反映できていたりできていないままだったりし得ます。
Let’s go through an illustrated example of how conflicts emerge and how to solve them in super slow motion. Figure 1, “Conflict management by example: step 1” illustrates the basic setup: we have two CouchDB databases, and we are replicating from database A to database B. To keep this simple, we assume triggered replication and not continuous replication, and we don’t replicate back from database B to A. All other replication scenarios can be reduced to this setup, so this explains everything we need to know.
ここでは、衝突がどのように起きて、それをどうやって解決するかをウルトラスローモーションで見ていきます。図4-1は基本的な状態を表します:ふたつのCouchDBインスタンスがあり、データベースAからデータベースBへレプリケーションしています。単純のために、継続的レプリケーションではなくトリガーによるレプリケーションを使い、データベースBからデータベースAへのレプリケーションは行わないこととしましょう。他の全てのレプリケーションシナリオは基本的にこの構成にまで単純化できますから、これで全てを説明できることになります。
Figure 1. Conflict management by example: step 1
Figure 1. 衝突管理の例 : step 1
We start out by creating a document in database A (Figure 2, “Conflict management by example: step 2”). Note the clever use of imagery to identify a specific revision of a document. Since we are not using continuous replication, database B won’t know about the new document for now.
まず、ドキュメントをデータベースAに作成するところから始めます。ドキュメントの絵が違うと、ドキュメントのバージョンが違うという意味になることに注意してください。継続的レプリケーションを行っていないので、この時点でデータベースBは新しいドキュメントについて何も知りません。

Figure 2. Conflict management by example: step 2
Figure 2. 衝突管理の例 : step 2
We now trigger replication and tell it to use database A as the source and database B as the target (Figure 3, “Conflict management by example: step 3”). Our document gets copied over to database B. To be precise, the latest revision of our document gets copied over.
今、データベースAをソース、データベースBをターゲットにしてトリガーレプリケーションを開始しました。私たちのドキュメントは無事にデータベースBにコピーされました。念のため、最新バージョンまでコピーされます。
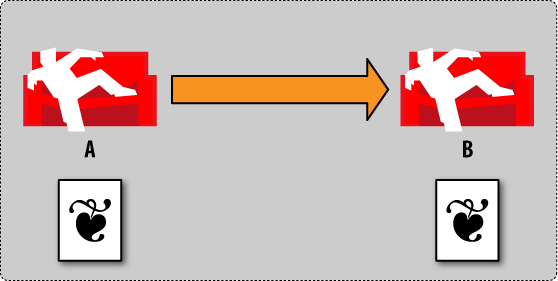
Figure 3. Conflict management by example: step 3
Figure 3. 衝突管理の例 : step 3
Now we go to database B and update the document (Figure 4, “Conflict management by example: step 4”). We change some values and upon change, CouchDB generates a new revision for us. Note that this revision has a new image. Node A is ignorant of any activity.
今度は、データベースBでドキュメントを更新してみましょう。更新によっていくつかの値を書き換えると、CouchDBは新しいリビジョンを作成します。このリビジョンは新しい絵になっています。サーバAはまだ何も知りません。
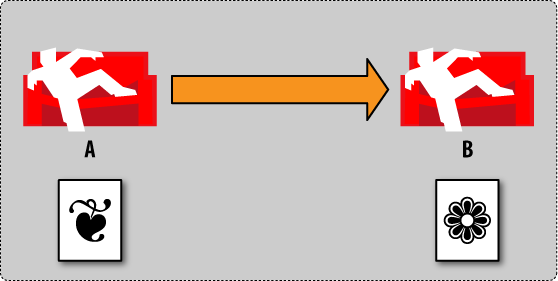
Figure 4. Conflict management by example: step 4
Figure 4. 衝突管理の例 : step 4
Now we make a change to our document in database A by changing some other values (Figure 5, “Conflict management by example: step 5”). See how it makes a different image for us to see the difference? It is important to note that this is still the same document. It’s just that there are two different revisions of that same document in each database.
今度は、データベースAでドキュメントのいくつかの値を更新しましょう。また違う絵になります。同じドキュメントじゃないということが分かりやすくなると思います。ここでは、それぞれのデータベースで同じドキュメントに単に異なるふたつのリビジョンがあるというだけです。
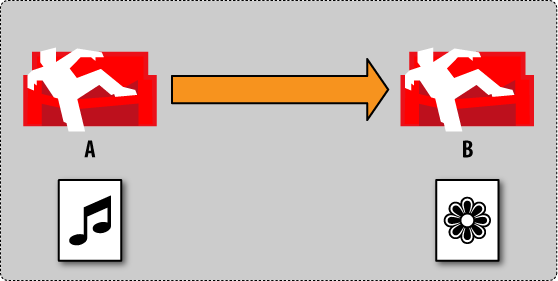
Figure 5. Conflict management by example: step 5
Figure 5. 衝突管理の例 : step 5
Now we trigger replication again from database A to database B as before (Figure 6, “Conflict management by example: step 6”). By the way, it doesn’t make a difference if the two databases live in the same CouchDB server or on different servers connected over a network.
今度は、以前と同様にデータベースAからデータベースBへトリガーレプリケーションをまた開始します。ところで、ひとつのサーバにふたつのデータベースが載っていようが、ふたつのサーバにそれぞれデータベースが載っていようが、話は同じです。
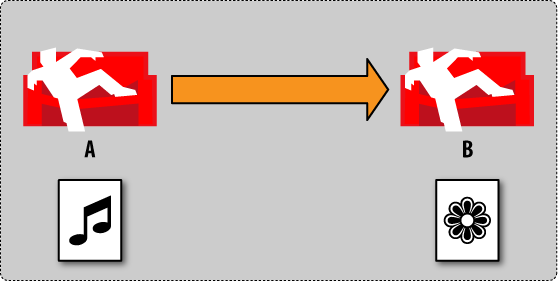
Figure 6. Conflict management by example: step 6
Figure 6. 衝突管理の例 : step 6
When replicating, CouchDB detects that there are two different revisions for the same document, and it creates a conflict (Figure 7, “Conflict management by example: step 7”). A document conflict means that there are now two latest revisions for this document.
レプリケーションをしているときにCouchDBはふたつの異なる新しいリビジョンが同じドキュメントについているのを検出し、衝突状態をつくります。ドキュメントの衝突は、ひとつのドキュメントにふたつの最新リビジョンがあることを意味します。

Figure 7. Conflict management by example: step 7
Figure 7. 衝突管理の例 : step 7
Finally, we tell CouchDB which version we would like to be the latest revision by resolving the conflict (Figure 8, “Conflict management by example: step 8”). Now both databases have the same data.
最終的には、CouchDBに対してどちらのリビジョンが最新であってほしいかを伝えることによって衝突を解決します。これでどちらのデータベースも同じ状態になりました。
Figure 8. Conflict management by example: step 8
Figure 8. 衝突管理の例 : step 8
Other possible outcomes include choosing the other revision and replicating that decision back to database A, or creating yet another revision in database B that includes parts of both conflicting revisions (a merge) and replicating that back to database A.
もう一方のリビジョンを選んでデータベースAにその決定を書き戻したり、双方をマージした別の新しいリビジョンをデータベースBで作って書き戻したりという選択もできます。
Now that we’ve walked through replication with pretty pictures, let’s get our hands dirty and see what the API calls and responses for this and other scenarios look like. We’ll be continuing Chapter 4, The Core API by using curl on the command line to make raw API requests.
ここまで、簡単な青写真でレプリケーションを概観してきましたが、実際に手を使って、どんなAPIコールとその戻り値がどんなシナリオになるのか見てみましょう。Core APIの章と同様に、コマンドラインからcurlで生のAPIリクエストを実行する方法をとります。
First, we create two databases that we can use for replication. These live on the same CouchDB instance, but they might as well live on a remote instance—CouchDB doesn’t care. To save us some typing, we create a shell variable for our CouchDB base URL that we want to talk to. We then create two databases, db and db-replica:
まず、レプリケーションするためにふたつのデータベースを作ります。これらは同じひとつのCouchDBインスタンス上に作りますが、離れたインスタンス上でも構いません。タイピングの手間を省くために、これから使うCouchDBのベースURLの環境変数を作っておきます。そして、dbとdb-replicaのふたつのデータベースを作ります:
HOST="http://127.0.0.1:5984"
> curl -X PUT $HOST/db
{"ok":true}
> curl -X PUT $HOST/db-replica
{"ok":true}
In the next step, we create a simple document {"count":1} in db and trigger replication to db-replica:
次のステップでは、単純なドキュメント { "count":1 } を db 上に作成し、db-replicaへレプリケーションします:
> curl -X PUT $HOST/db/foo -d '{"count":1}'
{"ok":true,"id":"foo","rev":"1-74620ecf527d29daaab9c2b465fbce66"}
> curl -X POST $HOST/_replicate -d '{"source":"db","target":"http://127.0.0.1:5984/db-replica"}'
{"ok":true,...,"docs_written":1,"doc_write_failures":0}]}
We skip a bit of the output of the replication session (see Chapter 16, Replication for details). If you see "docs_written":1 and "doc_write_failures":0, our document made it over to db-replica. We now update the document to {"count":2} in db-replica. Note that we now need to include the correct _rev property.
ここでは、レプリケーションのセッションの出力を少し省略します。詳細についてはレプリケーションの章を見てください。もしも "docs_written":1 と "doc_write_failures":0 があれば、新しいドキュメントは db-replica に作られています。次に、db-replica 上のドキュメントを {"count":2} に更新します。正しい _rev を渡していることに注意してください。
> curl -X PUT $HOST/db-replica/foo -d '{"count":2,"_rev":"1-74620ecf527d29daaab9c2b465fbce66"}'
{"ok":true,"id":"foo","rev":"2-de0ea16f8621cbac506d23a0fbbde08a"}
Next, we create the conflict! We change our document on db to {"count":3}. Our document is now logically in conflict, but CouchDB doesn’t know about it until we replicate again:
次は、衝突状態を作ります! db 上のドキュメントを {"count":3} に変更します。論理的には、これで衝突状態になります。しかし、CouchDBはもう一度レプリケーションすると、これに気付きます:
> curl -X PUT $HOST/db/foo -d '{"count":3,"_rev":"1-74620ecf527d29daaab9c2b465fbce66"}'
{"ok":true,"id":"foo","rev":"2-7c971bb974251ae8541b8fe045964219"}
> curl -X POST $HOST/_replicate -d '{"source":"db","target":"http://127.0.0.1:5984/db-replica"}'
{"ok":true,..."docs_written":1,"doc_write_failures":0}]}
To see that we have a conflict, we create a simple view in db-replica. The map function looks like this:
衝突状態を見るために、db-replica に簡単なビューを作ります。map関数は次のようになります:
function(doc) {
if(doc._conflicts) {
emit(doc._conflicts, null);
}
}
When we query this view, we get this result:
ビューを問い合わせると、次のような結果になります:
{"total_rows":1,"offset":0,"rows":[
{"id":"foo","key":["2-7c971bb974251ae8541b8fe045964219"],"value":null}
]}
The key here corresponds to the doc._conflicts property of our document in db-replica. It is an array listing all conflicting revisions. We see that the revision we wrote on db ({"count":3}) is in conflict. CouchDB’s automatic promotion of one revision to be the winning revision chose our first change ({"count":2}). To verify that, we just request that document from db-replica:
キーはここでは db-replica上にあるドキュメントの doc._conflicts プロパティに対応します。この配列には衝突しているリビジョンが全て含まれています。db 上に書き込まれたリビジョン ({"count":3}) が衝突状態にあることが分かります。CouchDBの最新リビジョンの自動選択により、最初の変更 ({"count":2}) が選ばれています。これを確認するために、db-replicaにもう一度問い合わせてみます:
> curl -X GET $HOST/db-replica/foo
{"_id":"foo","_rev":"2-de0ea16f8621cbac506d23a0fbbde08a","count":2}
To resolve the conflict, we need to determine which one we want to keep.
衝突を解決するためには、どのリビジョンを残しておきたいかを決めなければなりません。
How Does CouchDB Decide Which Revision to Use?
CouchDBはどのようにして使うべきリビジョンを決めるのでしょうか?
CouchDB guarantees that each instance that sees the same conflict comes up with the same winning and losing revisions. It does so by running a deterministic algorithm to pick the winner. The application should not rely on the details of this algorithm and must always resolve conflicts. We’ll tell you how it works anyway.
CouchDBはそれぞれのインスタンスが同じ衝突から同じ結果(採用されるリビジョンと、採用されないリビジョン)を保証します。どのリビジョンを採用するかを決めるアルゴリズムが決定論的だからです。アプリケーションは、このアルゴリズムの詳細に依存するべきではありませんし、衝突が起きたらその都度解決すべきです。
Each revision includes a list of previous revisions. The revision with the longest revision history list becomes the winning revision. If they are the same, the _rev values are compared in ASCII sort order, and the highest wins. So, in our example, 2-de0ea16f8621cbac506d23a0fbbde08a beats 2-7c971bb974251ae8541b8fe045964219.
それぞれのリビジョンは、以前のリビジョンを必ず保持しています。最も長いリビジョンの歴史を持つリビジョンが採用されます。もしも同じ長さのものが複数あった場合、_rev の値が ASCII 辞書順にソートされ、最も後ろにあるものが採用されます。 (TODO: AXX, ZXXの場合は後者が選択されることを確認した方がよいかも)
One advantage of this algorithm is that CouchDB nodes do not have to talk to each other to agree on winning revisions. We already learned that the network is prone to errors and avoiding it for conflict resolution makes CouchDB very robust.
Let’s say we want to keep the highest value. This means we don’t agree with CouchDB’s automatic choice. To do this, we first overwrite the target document with our value and then simply delete the revision we don’t like:
> curl -X DELETE $HOST/db-replica/foo?rev=2-de0ea16f8621cbac506d23a0fbbde08a
{"ok":true,"id":"foo","rev":"3-bfe83a296b0445c4d526ef35ef62ac14"}
> curl -X PUT $HOST/db-replica/foo -d '{"count":3,"_rev":"2-7c971bb974251ae8541b8fe045964219"}'
{"ok":true,"id":"foo","rev":"3-5d0319b075a21b095719bc561def7122"}
CouchDB creates yet another revision that reflects our decision. Note that the 3- didn’t get incremented this time. We didn’t create a new version of the document body; we just deleted a conflicting revision. To see that all is well, we check whether our revision ended up in the document.
CouchDBは我々の決定を反映したもうひとつのリビジョンを作成します。3-のリビジョンがインクリメントされていないことに注意してください。我々はドキュメントの新しいバージョンを作成したわけではなく、衝突していたリビジョンを削除しただけなのです。全て上手くいっていることを確認するために、最後にドキュメントを見ます。
> curl -X GET $HOST/db-replica/foo
{"_id":"foo","_rev":"3-5d0319b075a21b095719bc561def7122","count":3}
We also verify that our document is no longer in conflict by querying our conflicts view again, and we see that there are no more conflicts:
ここで、ビューを問い合わせることによってドキュメントがもはや衝突状態にないことをもう一度確認します:
{"total_rows":0,"offset":0,"rows":[
]}
Finally, we replicate from db-replica back to db by simply swapping source and target in our request to _replicate:
最後に、レプリケーションのソースとターゲットを入れ替えて、db-replicaからdbにデータを反映します。その際、_replicateメソッドを用います:
> curl -X POST $HOST/_replicate -d '{"target":"db","source":"http://127.0.0.1:5984/db-replica"}'
We see that our revision ends up in db, too:
そして、我々のリビジョンがdbに反映されていることも確認できます:
> curl -X GET $HOST/db/foo
{"_id":"foo","_rev":"3-5d0319b075a21b095719bc561def7122","count":3}
And we’re done.
これで完了です。
Let’s have a look at this revision ID: 3-5d0319b075a21b095719bc561def7122. Parts of the format might look familiar. The first part is an integer followed by a dash (3-). The integer increments for each new revision the document receives. Updates to the same document on multiple instances create their own independent increments. When replicating, CouchDB knows that there are two different revisions (like in our previous example) by looking at the second part.
リビジョンID "3-5d0319b075a21b095719bc561def7122" を少し見てみましょう。このフォーマットのそれぞれはよくご存知かもしれません。最初の部分は 整数の後ろにダッシュがついた形です(3-)。この整数は、新しいリビジョンになった際にインクリメントされます。複数のインスタンスで別々に同じドキュメントが更新された場合、それぞれインクリメントされます。レプリケーションの際に -以降の後半の部分を見ることによって、CouchDBはふたつの 2- とついたリビジョンが(これまでの例の通り)あることが分かります。
The second part is an md5-hash over a set of document properties: the JSON body, the attachments, and the _deleted flag. This allows CouchDB to save on replication time in case you make the same change to the same document on two instances. Earlier versions (0.9 and back) used random integers to specify revisions, and making the same change on two instances would result in two different revision IDs, creating a conflict where it was not really necessary. CouchDB 0.10 and above uses deterministic revision IDs using the md5 hash.
二番目の部分は、ドキュメントのプロパティ全て(つまり JSONのBody部分、添付ファイル、_deletedフラグ)から得られる md5ハッシュ値です。これによって、CouchDBが同じドキュメントに対する同じ変更を二つのインスタンスに適用する場合のレプリケーション時間を節約することができます。初期のバージョン(0.9以前)では、リビジョンを決めるのに乱数を用いてたので、同じ変更でも違うリビジョンIDがついてしまい、不要な衝突が発生してしまっていました。CouchDB 0.10以降では md5ハッシュを用いた決定論的なリビジョンIDをつけています。
For example, let’s create two documents, a and b, with the same contents:
試しに、決定論的なリビジョンIDが得られることを確かめるために、異なるドキュメント a と b を同じ内容で作成してみましょう。
> curl -X PUT $HOST/db/a -d '{"a":1}'
{"ok":true,"id":"a","rev":"1-23202479633c2b380f79507a776743d5"}
> curl -X PUT $HOST/db/b -d '{"a":1}'
{"ok":true,"id":"b","rev":"1-23202479633c2b380f79507a776743d5"}
Both revision IDs are the same, a consequence of the deterministic algorithm used by CouchDB.
This concludes our tour of the conflict management system. You should now be able to create distributed setups that deal with conflicts in a proper way.
これで衝突管理システム・ツアーは終わりです。あなたはもう、衝突を正しく解決できる分散システムのセットアップを作れるようになっているはずです!